
Dubletten gehören zu den häufigsten Problemen in Kunden-, Kontakt- und Adressbeständen. Sie entstehen unter anderem, wenn bereits vorhandene Kontakte bei der Suche nicht gefunden und erneut angelegt werden, Daten aus mehreren Systemen zusammengeführt werden oder Informationen in unterschiedlichen Schreibweisen vorliegen.
Die Folgen sind häufig unmittelbar spürbar:
- Kunden erhalten ein Mailing mehrfach.
- Kontakthistorien verteilen sich auf verschiedene Datensätze.
- Kundenzahlen und Auswertungen werden verfälscht.
- Marketing-, Porto- und Bearbeitungskosten steigen.
- Mitarbeiter arbeiten mit unterschiedlichen Informationen.
- Verträge, Vorgänge und Umsätze werden nicht eindeutig zugeordnet.
Doch nicht jeder ähnliche Datensatz ist automatisch eine Dublette. Umgekehrt können zwei sehr unterschiedlich aussehende Datensätze tatsächlich dieselbe Person oder dasselbe Unternehmen beschreiben.
Eine zuverlässige Dublettenerkennung muss deshalb mehr leisten als einen einfachen Vergleich von Namen und Anschriften.
Was ist eine Dublette?
Im Information Retrieval und im Datenmanagement werden zwei oder mehr Datensätze als Dubletten bezeichnet, wenn sie dasselbe Objekt der realen Welt beschreiben.
Dieses reale Objekt wird auch als Entität bezeichnet. Eine Entität kann beispielsweise sein:
- eine Person,
- ein Haushalt,
- ein Unternehmen,
- eine Niederlassung,
- ein Ansprechpartner,
- eine postalische Adresse.
Entscheidend ist daher nicht, ob zwei Datensätze exakt gleich aussehen. Entscheidend ist, ob sie im jeweiligen fachlichen Kontext dieselbe reale Entität repräsentieren.
Die Dublettenerkennung bezeichnet den Prozess, mit dem solche zusammengehörenden Datensätze ermittelt werden. Eine besondere Bedeutung besitzt sie bei der Datenbereinigung – beispielsweise nach der Zusammenführung verschiedener Datenbestände, deren Inhalte sich teilweise überschneiden.
Ein typischer Fall ist die Konsolidierung von Daten aus mehreren Systemen:
- CRM,
- ERP,
- Kundenservice,
- Marketingplattform,
- Webshop,
- Newsletter-System,
- Fachanwendungen.
Ein Kunde kann in mehreren dieser Systeme vorhanden sein, jedoch jeweils mit unterschiedlichen Schreibweisen, Aktualitätsständen oder Identifikationsmerkmalen.
Die zentrale Frage lautet deshalb nicht nur:
Sind diese Datensätze ähnlich?
Sondern:
Beschreiben diese Datensätze im jeweiligen fachlichen Kontext dieselbe reale Entität?
Der fachliche Kontext entscheidet
Welche Art von Dublette relevant ist, hängt vom jeweiligen Geschäftsprozess ab.
Betrachten wir zwei Personen:
Thomas Müller
Hauptstraße 1
76133 Karlsruhe
Sabine Müller
Hauptstraße 1
76133 Karlsruhe
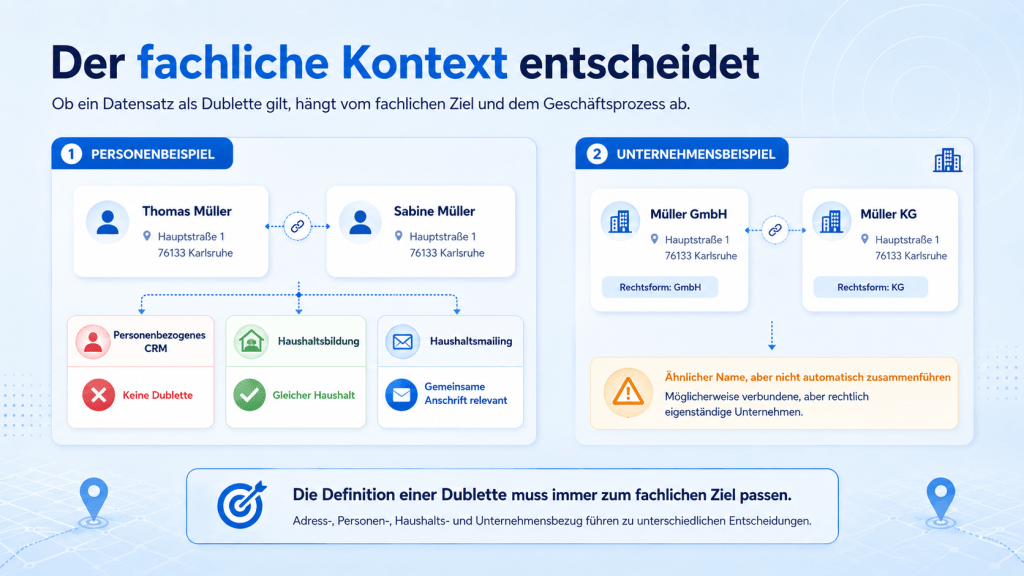
Beide Datensätze besitzen dieselbe Anschrift und denselben Nachnamen. Trotzdem handelt es sich sehr wahrscheinlich um zwei unterschiedliche Personen.
Für ein personenbezogenes CRM sind sie deshalb keine Dubletten. Für eine Haushaltsbildung können sie dagegen demselben Haushalt zugeordnet werden. Bei einem einmaligen Haushaltsmailing könnte wiederum die gemeinsame Anschrift das entscheidende Merkmal sein.
Ähnliches gilt für Unternehmen. Eine „Müller GmbH“ und eine „Müller KG“ können verbundene, aber rechtlich eigenständige Unternehmen sein. Sie dürfen nicht allein aufgrund des ähnlichen Namens und derselben Anschrift zusammengeführt werden.
Die Definition einer Dublette muss deshalb immer zum fachlichen Ziel passen.
Vier typische Arten von Dubletten
Dubletten können sehr unterschiedlich aussehen. Für die praktische Arbeit lassen sie sich in vier typische Gruppen einteilen.
Diese Einteilung hilft dabei, geeignete Such-, Vergleichs- und Bereinigungsverfahren auszuwählen.
1. Echte Duplikate: vollständig identische Datensätze
Echte Duplikate sind exakte Kopien. Alle betrachteten Zeichen und Werte stimmen vollständig überein.
Beispiel
Datensatz A
Max Mustermann
Hauptstraße 1
76133 Karlsruhe
Datensatz B
Max Mustermann
Hauptstraße 1
76133 Karlsruhe
Solche Duplikate entstehen häufig durch:
- versehentliches Kopieren von Datensätzen,
- mehrfach ausgeführte Importe,
- wiederholte Verarbeitung derselben Quelldatei,
- fehlende technische Eindeutigkeitsprüfungen,
- fehlerhafte Synchronisationsprozesse.
Echte Duplikate lassen sich technisch vergleichsweise einfach erkennen. Häufig verhindern bereits Datenbankregeln, eindeutige Identifikationsnummern oder technische Schlüssel das erneute Speichern eines vollständig identischen Eintrags.
Trotzdem sollte vor einer Löschung oder Zusammenführung geprüft werden, ob mit den identischen Stammdaten unterschiedliche Vorgänge, Verträge oder Kundenbeziehungen verbunden sind.
Identische Adressdaten bedeuten nicht automatisch, dass sämtliche zugehörigen Geschäftsdaten zusammengeführt werden dürfen.
2. Semantische Dubletten: Tippfehler, Abkürzungen und Namensvarianten
Semantische Dubletten beschreiben dieselbe reale Person, Organisation oder Adresse, obwohl die gespeicherten Werte voneinander abweichen.
Beispiele:
- Max Mustermann und Maximilian Mustermann
- Müller und Mueller
- Schmidt und Schmitt
- Hauptstraße und Hauptstr.
- Köln und Koeln
- ABC Maschinenbau GmbH und ABC Maschinenbau Gesellschaft mbH
Solche Dubletten lassen sich nicht zuverlässig mit einem einfachen exakten Vergleich finden.
Für ihre Erkennung werden unter anderem benötigt:
- Normalisierung,
- phonetische Suche,
- fehlertolerante Vergleiche,
- Regeln für Abkürzungen und Namensvarianten,
- gewichtete Ähnlichkeitswerte.
Allerdings ist semantische Ähnlichkeit zunächst nur ein Hinweis.
„Max“ kann eine Kurzform von „Maximilian“ sein. Max kann aber auch der tatsächlich eingetragene Vorname einer anderen Person sein. Ebenso können zwei Unternehmen mit ähnlichen Namen rechtlich voneinander unabhängig sein.
Weitere Merkmale müssen die Entscheidung absichern.
3. Strukturelle Dubletten: unterschiedliche Formate und Erfassungsregeln
Bei strukturellen Dubletten sind die enthaltenen Informationen fachlich möglicherweise gleich, wurden aber in unterschiedlichen Formaten oder Datenstrukturen gespeichert.
Beispiele:
- Hauptstraße 1 in einem gemeinsamen Feld
Straße: Hauptstraße und Hausnummer: 1 in getrennten Feldern - 0721 123456
+49 721 123456 - 31.12.2025
12/31/2025 - Müller, Max
Max Müller
Auch unterschiedliche Erfassungsrichtlinien können strukturelle Abweichungen verursachen.
Ein CRM speichert Straße und Hausnummer möglicherweise gemeinsam, während das ERP beide Angaben in getrennten Feldern führt. Ein System nutzt das deutsche Datumsformat, ein anderes das amerikanische Format. In einer Anwendung wird der Ländercode in der Telefonnummer gespeichert, in einer anderen nicht.
Vor der eigentlichen Dublettenprüfung müssen solche Daten deshalb:
- strukturiert,
- in Einzelfelder zerlegt,
- in gemeinsame Formate überführt,
- und normalisiert werden.
Ohne diese Vorbereitung können selbst fachlich identische Werte als unterschiedlich bewertet werden.
4. Partielle Dubletten: teilweise übereinstimmende oder widersprüchliche Daten
Partielle Dubletten beschreiben vermutlich dieselbe Entität, enthalten aber nur teilweise übereinstimmende oder sogar widersprüchliche Informationen.
Beispiel
Datensatz A
Max Mustermann
aktuelle Telefonnummer
alte E-Mail-Adresse
Datensatz B
Max Mustermann
alte Telefonnummer
aktuelle E-Mail-Adresse
Beide Datensätze können zur selben Person gehören. Ein einfaches Überschreiben wäre jedoch riskant, weil dadurch jeweils eine aktuelle Information verloren gehen könnte.
Weitere typische Fälle sind:
- alte und neue Anschrift,
- private und geschäftliche E-Mail-Adresse,
- mehrere gültige Telefonnummern,
- aktueller und früherer Firmenname,
- unterschiedliche Ansprechpartner,
- unterschiedliche Änderungszeitpunkte,
- abweichende Angaben aus mehreren Quellsystemen.
Bei partiellen Dubletten reicht es nicht aus, nur zu entscheiden, ob zwei Datensätze zusammengehören.
Für jedes einzelne Merkmal muss zusätzlich geprüft werden:
- Welcher Wert ist aktueller?
- Welche Quelle ist verlässlicher?
- Wurde ein Wert postalisch oder anderweitig bestätigt?
- Können mehrere Werte gleichzeitig gültig sein?
- Soll ein früherer Wert historisch erhalten bleiben?
- Darf ein Wert automatisch überschrieben werden?
Gerade bei partiellen Dubletten wird deutlich, dass Dublettenerkennung und Golden-Record-Bildung zwei unterschiedliche Aufgaben sind.
Die Dublettenerkennung beantwortet:
Gehören diese Datensätze wahrscheinlich zur selben Entität?
Die Golden-Record-Bildung beantwortet anschließend:
Welche Informationen sollen in den konsolidierten Datensatz übernommen werden?
Warum entstehen unterschiedliche Darstellungen?
Dass zusammengehörende Datensätze unterschiedlich aussehen, kann zahlreiche Ursachen haben.
Inhaltliche oder semantische Fehler
Die gespeicherten Informationen entsprechen nicht oder nicht mehr der Realität.
Beispiele:
- Eine Person ist umgezogen.
- Ein Unternehmen hat seinen Standort gewechselt.
- Ein Ansprechpartner hat das Unternehmen verlassen.
- Eine Telefonnummer wurde abgeschaltet.
- Ein Firmenname oder eine Rechtsform hat sich geändert.
Syntaktische oder strukturelle Fehler
Die Angaben sind grundsätzlich korrekt, befinden sich aber in der falschen Struktur oder im falschen Feld.
Beispiele:
- Vorname und Nachname sind vertauscht.
- Straße und Hausnummer stehen im Ortsfeld.
- Der Firmenname wurde als Ansprechpartner erfasst.
- Mehrere Informationen befinden sich in einem einzigen Freitextfeld.
Lexikalische, phonetische und namensbezogene Varianten
Namen oder Begriffe können unterschiedlich geschrieben werden, obwohl sie gleich oder ähnlich klingen. Zusätzlich können Kurzformen, Rufnamen oder regional gebräuchliche Namensvarianten verwendet werden.
Beispiele:
- Maier, Mayer, Meier und Meyer
- Schmidt und Schmitt
- Köln und Koeln
- Müller und Mueller
- Josef, Joseph, Jupp, Sepp
- Stephanie, Stefanie, Steffi
Bei den letzten beiden Beispielen handelt es sich nicht nur um unterschiedliche Schreibweisen. Jupp und Sepp beziehungsweise Steffi sind Kurz- oder Rufnamen, die einer Person zugeordnet sein können, aber nicht zwangsläufig dieselbe Person bezeichnen.
Solche Varianten sollten deshalb zur Bildung möglicher Dublettenkandidaten genutzt werden. Für eine automatische Zusammenführung sind zusätzliche Merkmale wie Anschrift, Geburtsdatum, E-Mail-Adresse oder Kundennummer erforderlich.

Typografische Fehler
Bei der Eingabe wurden Zeichen ausgelassen, ergänzt oder vertauscht.
Beispiele:
- Mustermann und Mustreman
- Hauptstraße und Haupstraße
- Schneider und Schnieder
Kodierungsfehler
Unterschiedliche Zeichencodierungen können dazu führen, dass Umlaute und Sonderzeichen falsch dargestellt werden.
Beispiele:
- Müller wird als Müller dargestellt.
- Straße wird fehlerhaft gespeichert.
- Akzente oder internationale Schriftzeichen gehen verloren.
Eine zuverlässige Dublettenerkennung muss deshalb fehlertolerant sein und mit mehreren Arten von Abweichungen umgehen können.
Unterschiedliche Schreibweisen derselben Firma
Betrachten wir zwei beispielhafte Firmendatensätze:
Datensatz A
Müller GmbH
Hauptstraße 7
50667 Köln
Datensatz B
Mueller Gesellschaft mbH
Hauptstr. 7
50667 Koeln
Es spricht einiges dafür, dass beide Datensätze dasselbe Unternehmen beschreiben:
- Müller und Mueller sind alternative Schreibweisen.
- GmbH und Gesellschaft mbH bezeichnen dieselbe Rechtsform.
- Hauptstraße und Hauptstr. können normalisiert werden.
- Köln und Koeln sind orthografische Varianten.
- Postleitzahl und Hausnummer stimmen überein.
Trotzdem sollte eine automatische Zusammenführung nicht allein aufgrund dieser Ähnlichkeiten erfolgen.
Zusätzliche Merkmale können die Entscheidung absichern:
- Handelsregisternummer,
- Umsatzsteuer-Identifikationsnummer,
- interne Geschäftspartnernummer,
- Telefonnummer,
- E-Mail-Domain,
- Website,
- Bankverbindung,
- Herkunftssystem.
Ähnliche Namen können unterschiedliche Unternehmen bezeichnen
Anders sieht es bei folgenden Einträgen aus:
- Müller GmbH
- Müller KG
Die Namen sind ähnlich, die Rechtsformen unterscheiden sich jedoch. Es kann sich um zwei eigenständige juristische Personen handeln.
Auch dieselbe Anschrift ist kein eindeutiger Beweis für eine Dublette. Tochtergesellschaften, Niederlassungen oder verbundene Unternehmen können denselben Standort nutzen.
Eine unkritische Zusammenführung könnte dazu führen, dass:
- Verträge falsch zugeordnet werden,
- Rechnungs- und Lieferinformationen vermischt werden,
- Ansprechpartner beim falschen Unternehmen erscheinen,
- eigenständige Geschäftsbeziehungen verloren gehen,
- rechtlich getrennte Unternehmen zu einem Datensatz verschmelzen.
Bei Unternehmensdaten müssen daher Rechtsform, Registerinformationen, Niederlassungen und Konzernbeziehungen berücksichtigt werden.
Welche Merkmale sollten verglichen werden?
Für die Dublettenerkennung können unterschiedliche Informationen herangezogen werden.
Bei Personen
- Vorname und Nachname
- frühere Namen
- Geburtsdatum
- postalische Anschrift
- E-Mail-Adresse
- Telefonnummer
- Kundennummer
- Vertrags- oder Kontonummer
- Herkunftssystem
- Aktualisierungszeitpunkt
Bei Unternehmen
- Firmenname
- Rechtsform
- Anschrift
- Niederlassung
- Telefonnummer
- E-Mail-Domain
- Website
- Handelsregisternummer
- Umsatzsteuer-Identifikationsnummer
- interne Geschäftspartnernummer
- Unternehmens- oder Konzernzugehörigkeit
Nicht jedes Merkmal besitzt dieselbe Aussagekraft.
Eine übereinstimmende Handelsregisternummer ist wesentlich aussagekräftiger als ein ähnlicher Firmenname. Eine identische Kundennummer kann ein starkes Merkmal sein. Dieselbe Postleitzahl allein besitzt dagegen kaum Aussagekraft.
Auch häufige Begriffe wie „GmbH“, „Straße“ oder „Deutschland“ unterscheiden Datensätze nur wenig. Seltene Namen, eindeutige Nummern und spezifische Kontaktmerkmale können wesentlich stärker gewichtet werden.
Exakte Vergleiche reichen nicht aus
In realen Datenbeständen treten zahlreiche Abweichungen auf:
- Müller und Mueller
- Maier, Mayer, Meier und Meyer
- Hauptstraße und Hauptstr.
- Frankfurt am Main und Frankfurt/Main
- Thomas-Christian und Thomas Christian
- ABC Maschinenbau GmbH und ABC Maschinenbau Gesellschaft mbH
Ein rein exakter Vergleich würde viele tatsächliche Dubletten nicht erkennen.
Deshalb werden häufig verschiedene Verfahren miteinander kombiniert.
Normalisierung
Bei der Normalisierung werden Werte in einheitliche Vergleichsformate überführt.
Mögliche Schritte sind:
- Groß- und Kleinschreibung vereinheitlichen,
- überflüssige Leerzeichen entfernen,
- Satzzeichen berücksichtigen oder entfernen,
- Umlaute und Sonderzeichen vereinheitlichen,
- internationale Schriftzeichen bei Bedarf transliterieren,
- Straßenabkürzungen standardisieren,
- Telefonnummern normalisieren,
- Rechtsformen vereinheitlichen,
- Datumsangaben in ein gemeinsames Format überführen.
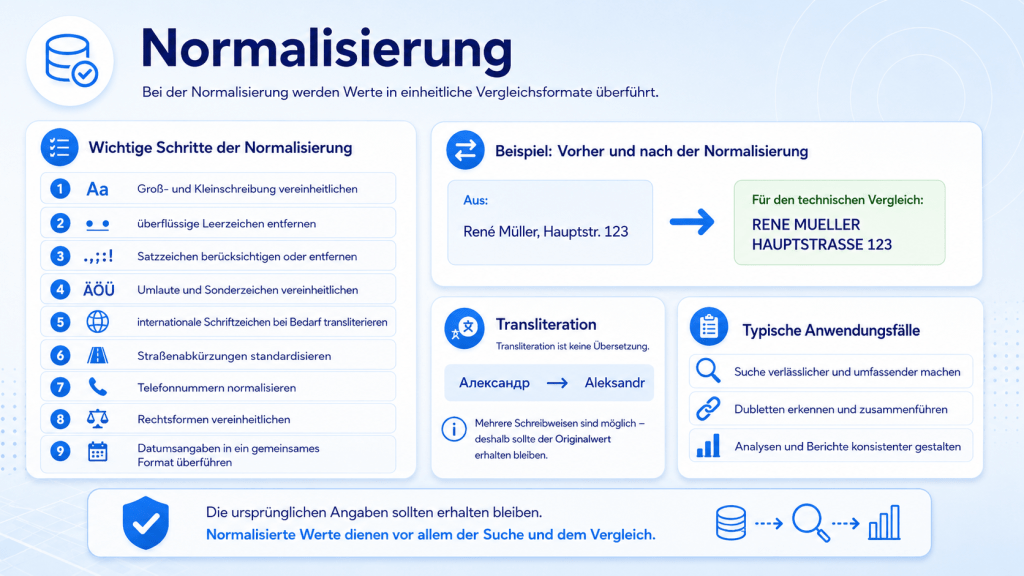
Aus:
René Müller, Hauptstr. 123
kann für den technischen Vergleich beispielsweise werden:
RENE MUELLER HAUPTSTRASSE 123
Die ursprünglichen Angaben sollten trotzdem erhalten bleiben. Normalisierte Werte dienen vor allem der Suche und dem Vergleich.
Wichtig ist: Transliteration ist keine Übersetzung. Sie überführt Zeichen aus einem Schriftsystem in ein anderes, beispielsweise „Александр“ in „Aleksandr“. Dabei können mehrere mögliche Schreibweisen entstehen, weshalb der Originalwert erhalten bleiben sollte.
Phonetische Suche
Phonetische Verfahren unterstützen die Suche nach gleich oder ähnlich klingenden Namen.
So können Varianten wie Maier, Mayer, Meier und Meyer als mögliche Treffer erkannt werden.
Phonetische Ähnlichkeit ist jedoch kein Beweis für eine Dublette. Sie dient vor allem dazu, mögliche Kandidaten zu finden, die anschließend anhand weiterer Merkmale geprüft werden.
Normalisierung selbst ausprobieren
Wie sich unterschiedliche Schreibweisen in einheitliche Vergleichswerte überführen lassen, können Sie in unserem Demoprogramm selbst ausprobieren.
Wählen Sie optional das Land aus und geben Sie anschließend eine Anschrift oder eine frei formulierte Zeile ein. Die Demo zeigt, wie die Eingabe analysiert und für die weitere Verarbeitung standardisiert werden kann.
Standardisierung im Demoprogramm testen
Fehlertoleranter Vergleich
Fuzzy-Matching-Verfahren berücksichtigen unter anderem:
- Tippfehler,
- Buchstabendreher,
- fehlende Zeichen,
- zusätzliche Zeichen,
- abweichende Wortreihenfolgen,
- Abkürzungen,
- alternative Schreibweisen.
Zu den bekannten Verfahren gehören beispielsweise:
- Levenshtein-Distanz,
- Damerau-Levenshtein-Distanz,
- Jaro-Winkler-Ähnlichkeit,
- N-Gramm- und Trigramm-Vergleiche,
- Kosinus-Ähnlichkeit,
- kombinierte beziehungsweise hybride Verfahren.
Keines dieser Verfahren löst jeden Anwendungsfall optimal. Die Auswahl hängt von der Art der Daten und den erwarteten Abweichungen ab.
Eine Edit-Distanz eignet sich beispielsweise gut für einzelne Tippfehler. Eine tokenbasierte Kosinus-Ähnlichkeit kann besser mit vertauschten Namensbestandteilen umgehen. Phonetische Verfahren helfen bei gleich klingenden, aber unterschiedlich geschriebenen Namen.
In der Praxis ist deshalb häufig eine Kombination mehrerer Verfahren sinnvoll.
Von Einzelmerkmalen zum Match-Score
Bei einer modernen Dublettenerkennung werden Merkmale nicht nur mit „gleich“ oder „ungleich“ bewertet.
Stattdessen kann für jedes Feld ein eigener Ähnlichkeitswert berechnet werden.
Ein vereinfachtes Beispiel:
- Firmenname: 91 Punkte
- Straße: 96 Punkte
- Hausnummer: vollständige Übereinstimmung
- Postleitzahl: vollständige Übereinstimmung
- Ort: 98 Punkte
- Telefonnummer: keine Übereinstimmung
- E-Mail-Domain: vollständige Übereinstimmung
Aus diesen Einzelwerten wird ein gesamter Match-Score gebildet.
Dabei sollten die Merkmale unterschiedlich gewichtet werden. Eine eindeutige Identifikationsnummer besitzt beispielsweise mehr Gewicht als ein ähnlicher Ortsname.
Auch fehlende Informationen müssen anders bewertet werden als widersprüchliche Informationen.
Ein nicht vorhandener Telefonnummernwert bedeutet:
Es kann keine Aussage getroffen werden.
Zwei unterschiedliche Telefonnummern können dagegen bedeuten:
Es liegt ein Widerspruch vor – oder beide Nummern sind gültig.
Das Ergebnis kann beispielsweise in drei Bereiche unterteilt werden:
- Hoher Match-Score: sehr wahrscheinliche Dublette
- Mittlerer Match-Score: manuelle Prüfung erforderlich
- Niedriger Match-Score: vermutlich unterschiedliche Entitäten
Die konkreten Grenzwerte müssen zum jeweiligen Datenbestand, Geschäftsprozess und Fehlerrisiko passen.
Hohe Ähnlichkeit bedeutet nicht automatisch hohe Sicherheit
Ein besonders wichtiger Punkt ist die Unterscheidung zwischen Ähnlichkeit und Verlässlichkeit der Entscheidung.
Betrachten wir zwei unvollständige Datensätze:
Datensatz A
Peter
Datensatz B
Peter
Die vorhandenen Angaben stimmen zu identisch überein. Trotzdem ist die Informationsbasis viel zu gering, um daraus eine sichere Personendublette abzuleiten.
Anders sieht es hier aus:
Datensatz A
Peter Müller
Hauptstraße 123
76133 Karlsruhe
Datensatz B
Peter Müller
Hauptstraße 123
76133 Karlsruhe
Auch hier beträgt die Ähnlichkeit 100 Punkte. Aufgrund der höheren Vollständigkeit ist die Entscheidung jedoch wesentlich belastbarer.
Neben dem eigentlichen Match-Score sollte deshalb auch bewertet werden:
- Wie vollständig sind die Datensätze?
- Wie aussagekräftig sind die übereinstimmenden Merkmale?
- Gibt es relevante Widersprüche?
- Wie zuverlässig sind die Quellen?
- Wie aktuell sind die Informationen?
Ein hoher Ähnlichkeitswert bei wenigen vorhandenen Angaben darf nicht mit einer sicheren Identifizierung verwechselt werden.
Falsch positive und falsch negative Entscheidungen
Bei der Dublettenerkennung gibt es zwei zentrale Fehlerarten.
Falsch positiv
Zwei unterschiedliche Personen oder Unternehmen werden irrtümlich als Dublette eingestuft und zusammengeführt.
Dieser Fehler ist besonders kritisch, weil Informationen verschiedener Kunden vermischt werden können.
Mögliche Folgen:
- falsche Vertragszuordnungen,
- Datenschutzprobleme,
- fehlerhafte Rechnungen,
- vermischte Kontakthistorien,
- Verlust eigenständiger Geschäftsbeziehungen.
Falsch negativ
Zwei Datensätze beschreiben tatsächlich dieselbe Entität, werden aber nicht als Dublette erkannt.
Die Dublette bleibt dadurch im Datenbestand bestehen.
Mögliche Folgen:
- doppelte Mailings,
- verteilte Kundenhistorien,
- falsche Kundenzahlen,
- mehrfach angelegte Vorgänge,
- unvollständige Customer-360-Sicht.
Zwischen beiden Fehlerarten besteht ein Zielkonflikt.
Großzügige Regeln und niedrige Schwellwerte finden mehr tatsächliche Dubletten, erzeugen aber auch mehr falsch positive Kandidaten. Strenge Regeln reduzieren das Risiko falscher Zusammenführungen, lassen jedoch mehr Dubletten unerkannt.
Trefferquote und Genauigkeit
Die Qualität einer Dublettenerkennung kann unter anderem mit zwei Kennzahlen bewertet werden.
Trefferquote beziehungsweise Recall
Die Trefferquote beschreibt, welcher Anteil der tatsächlich vorhandenen Dubletten gefunden wurde.
Eine hohe Trefferquote bedeutet:
Das Verfahren übersieht nur wenige tatsächliche Dubletten.
Genauigkeit beziehungsweise Precision
Die Genauigkeit beschreibt, welcher Anteil der als Dubletten erkannten Kandidaten tatsächlich Dubletten ist.
Eine hohe Genauigkeit bedeutet:
Unter den vorgeschlagenen Kandidaten befinden sich nur wenige falsche Treffer.
Ein System, das nahezu jeden ähnlichen Datensatz als Dublette einstuft, erreicht möglicherweise eine hohe Trefferquote, aber eine geringe Genauigkeit.
Ein System, das nur bei nahezu vollständiger Übereinstimmung einen Treffer meldet, erreicht möglicherweise eine hohe Genauigkeit, übersieht aber viele echte Dubletten.
Der optimale Schwellwert hängt vom Anwendungsfall ab.
Bei einer automatischen Zusammenführung personenbezogener Daten muss das Risiko falsch positiver Entscheidungen besonders gering sein. Bei einer Arbeitsliste für die manuelle Prüfung kann eine höhere Trefferquote wichtiger sein.
Nicht jede Dublette sollte automatisch zusammengeführt werden
Ein praxisgerechter Prozess kann drei Entscheidungswege vorsehen.
Automatische Verarbeitung
Sie eignet sich für Treffer, bei denen mehrere starke Identifikationsmerkmale eindeutig übereinstimmen und keine relevanten Widersprüche bestehen.
Manuelle Prüfung
Unsichere Fälle werden einem Sachbearbeiter gegenübergestellt.
Mögliche Entscheidungen:
- zusammenführen,
- getrennt lassen,
- später erneut prüfen,
- zusätzliche Informationen anfordern,
- einen führenden Datensatz auswählen.
Keine Zusammenführung
Datensätze bleiben getrennt, wenn die Übereinstimmungen nicht ausreichen oder eindeutige Widersprüche vorliegen.
Jede Entscheidung sollte nachvollziehbar dokumentiert werden:
- Welche Merkmale wurden verglichen?
- Welche Ähnlichkeitswerte wurden berechnet?
- Welche Regeln wurden ausgelöst?
- Welche Widersprüche lagen vor?
- Wurde automatisch oder manuell entschieden?
- Wer hat die Entscheidung getroffen?
Was passiert nach der Dublettenerkennung?
Die Erkennung einer möglichen Dublette ist nur der erste Schritt.
Anschließend muss entschieden werden, welche Informationen in den gemeinsamen Datensatz übernommen werden.
Beispielsweise können zwei Datensätze unterschiedliche Anschriften, Telefonnummern oder E-Mail-Adressen enthalten.
Dann stellen sich Fragen wie:
- Welcher Wert ist aktueller?
- Welches Quellsystem ist führend?
- Welche Angabe wurde bestätigt?
- Darf ein Wert automatisch überschrieben werden?
- Können mehrere Werte parallel gültig sein?
- Soll ein älterer Wert historisiert werden?
Aus den verlässlichsten Informationen kann ein Golden Record entstehen.
Dieser sollte nicht nur die ausgewählten Werte enthalten, sondern auch dokumentieren:
- aus welchen Quelldatensätzen er gebildet wurde,
- welche Regeln angewendet wurden,
- welche Werte übernommen wurden,
- welche Werte nicht übernommen wurden,
- wann die Entscheidung erfolgte,
- ob sie automatisch oder manuell getroffen wurde.
Die technische Dublettenerkennung liefert somit Kandidaten und Bewertungsgrundlagen. Das tatsächliche Zusammenführen und die Auswahl der führenden Werte benötigen zusätzlich fachliches Wissen.
Dublettenerkennung ist ein kontinuierlicher Prozess
Eine einmalige Dublettenbereinigung verbessert den vorhandenen Bestand, verhindert aber nicht, dass neue Dubletten entstehen.
Neue Datensätze gelangen fortlaufend in die Systeme:
- über Webformulare,
- durch manuelle Neuanlagen,
- über Importe,
- aus verbundenen Systemen,
- bei Migrationen,
- über externe Datenanbieter,
- durch Unternehmenszusammenschlüsse.
Deshalb sollte Dublettenerkennung an mehreren Stellen ansetzen:
- bei der Suche vor einer Neuanlage,
- während der Dateneingabe,
- bei Datenimporten,
- beim Zusammenführen mehrerer Systeme,
- durch regelmäßige Prüfung des Gesamtbestands.
Besonders wirksam ist eine fehlertolerante Suche bereits vor dem Anlegen eines neuen Kontakts. Wird ein vorhandener Kunde rechtzeitig gefunden, entsteht die Dublette gar nicht erst.
Welche Rolle kann Databricks spielen?
Bei großen Datenbeständen oder mehreren Quellsystemen kann Databricks die technische Verarbeitung unterstützen.
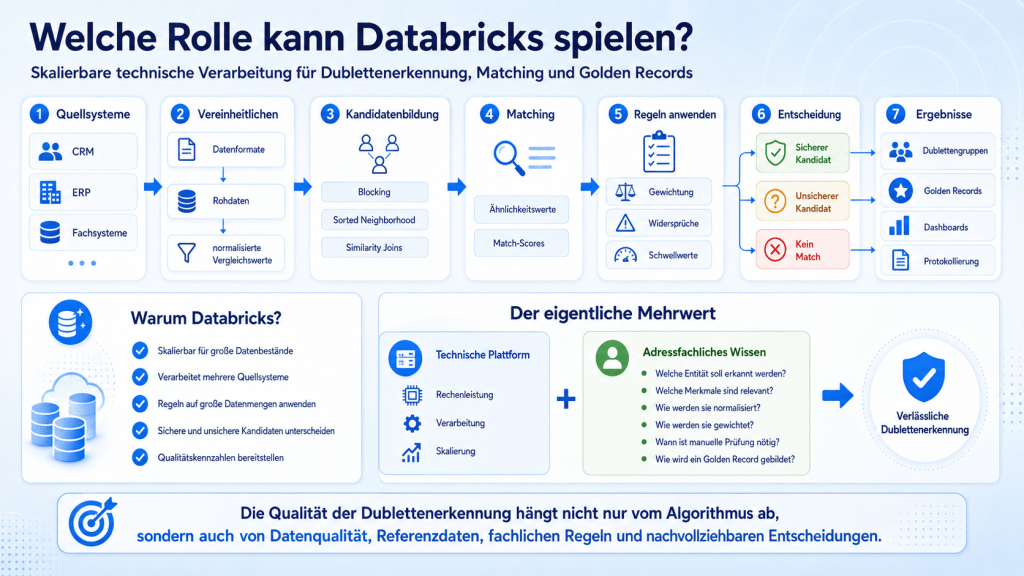
Eine skalierbare Plattform kann beispielsweise:
- Daten aus CRM-, ERP- und Fachsystemen übernehmen,
- unterschiedliche Datenformate vereinheitlichen,
- Rohdaten und normalisierte Vergleichswerte getrennt speichern,
- Dublettenkandidaten effizient bilden,
- Ähnlichkeitswerte und Match-Scores berechnen,
- unterschiedliche Regeln auf große Datenmengen anwenden,
- sichere und unsichere Kandidaten unterscheiden,
- Dublettengruppen erzeugen,
- Golden Records bilden,
- Entscheidungen und Verarbeitungsschritte protokollieren,
- Qualitätskennzahlen in Dashboards bereitstellen.
Gerade bei großen Beständen ist es nicht effizient, jeden Datensatz mit jedem anderen Datensatz vollständig zu vergleichen.
Stattdessen können zunächst Kandidatengruppen gebildet werden. Typische Verfahren sind beispielsweise:
- Blocking,
- Sorted Neighborhood,
- indexbasierte Kandidatensuche,
- Similarity Joins,
- mehrstufige Vergleichsverfahren.
Databricks bietet die notwendige Rechenleistung und Skalierbarkeit, um solche Verfahren auf umfangreiche Datenbestände anzuwenden.
Die Plattform entscheidet jedoch nicht von selbst, welche Datensätze fachlich zusammengehören.
Der eigentliche Mehrwert entsteht durch die Kombination aus technischer Plattform und adressfachlichem Wissen:
- Welche Entität soll erkannt werden?
- Welche Merkmale sind relevant?
- Wie werden die Merkmale normalisiert?
- Wie werden sie gewichtet?
- Welche Widersprüche verhindern eine Zusammenführung?
- Ab welchem Score ist eine automatische Entscheidung zulässig?
- Wann ist eine manuelle Prüfung erforderlich?
- Welche Quelle liefert den führenden Wert?
- Wie wird ein Golden Record gebildet?
Die Qualität der Dublettenerkennung hängt deshalb nicht nur vom verwendeten Algorithmus ab. Entscheidend sind ebenso die Datenqualität, Referenzdaten, fachlichen Regeln und nachvollziehbaren Entscheidungsprozesse.
Wie hoch ist das Dublettenpotenzial in Ihrem Datenbestand?
Mit einem Address Quality Quick Scan untersuchen wir zunächst eine repräsentative Stichprobe Ihrer Kunden- und Adressdaten.
Dabei analysieren wir unter anderem:
- typische Dublettenarten und Fehlerbilder,
- mögliche Dublettenkandidaten,
- Vollständigkeit und Aussagekraft der verfügbaren Merkmale,
- unterschiedliche Schreibweisen und Datenformate,
- geeignete Matching- und Normalisierungsverfahren,
- sowie das Potenzial für verlässliche Golden Records.
Sie erhalten eine transparente Einschätzung der Datenqualität und konkrete Empfehlungen für das weitere Vorgehen.
Fazit
Dubletten sind nicht gleich Dubletten.
Exakte Kopien sind lediglich der einfachste Fall. In der Praxis unterscheiden sich zusammengehörende Datensätze häufig durch Tippfehler, Namensvarianten, unterschiedliche Formate, veraltete Informationen oder widersprüchliche Angaben.
Gleichzeitig können sehr ähnliche Datensätze unterschiedliche Personen, Haushalte oder Unternehmen beschreiben.
Eine zuverlässige Dublettenerkennung kombiniert deshalb:
- eine klare fachliche Definition der gesuchten Entität,
- Datenanalyse und Normalisierung,
- phonetische und fehlertolerante Suchverfahren,
- Synonyme
- mehrere Vergleichsmerkmale,
- gewichtete Match-Scores,
- die Bewertung von Vollständigkeit und Verlässlichkeit,
- fachliche Entscheidungsregeln,
- eine manuelle Prüfung unsicherer Fälle,
- und eine nachvollziehbare Golden-Record-Bildung.
Das Ziel besteht nicht darin, möglichst viele Datensätze zusammenzuführen.
Das Ziel besteht darin, die richtigen Datensätze mit ausreichender Sicherheit zusammenzuführen.
Mit einem Address Quality Quick Scan kann zunächst eine repräsentative Stichprobe untersucht werden. Dabei lässt sich feststellen:
- welche Arten von Dubletten im Bestand vorkommen,
- wie hoch das mögliche Dublettenpotenzial ist,
- welche Fehlerbilder besonders häufig auftreten,
- welche Merkmale für das Matching geeignet sind,
- und welche Verfahren sich für den jeweiligen Datenbestand anbieten.
So entsteht eine belastbare Grundlage für die Bereinigung des Bestands und die Entwicklung verlässlicher Golden Records.
Ein Address Quality Quick Scan bietet einen pragmatischen Einstieg, um Dublettenpotenziale sichtbar zu machen und geeignete Bereinigungs- und Matching-Verfahren für den eigenen Datenbestand abzuleiten.
