Immer wieder werden wir gefragt, ob die Software auch „Phonetik“ kann oder wir bekommen die konkrete Anforderung „unser System muss den Soundex unterstützen“.
Daraufhin stellen wir die Frage, was mit der „Phonetik“ erreicht werden soll. Meist steckt hinter dieser Anforderung der Wunsch nach einer Fehlertoleranz. Viele Kunden können es weiter präzisieren und formulieren die Anforderung auf folgende Art: „Aussprachefehler in der Sucheingabe sollen den gewünschten Datensatz finden“ oder „gleichklingende Namen sollen von der Suchengine gefunden werden“. Sehr prominente Beispiele:
- Maier – Meier – Mejer – Meyer
- Schmid – Schmidt – Schmitt
- Stefan – Stephan
- Katharina – Katarina
- Stuttgart – Stutgart
Diese Anforderung zur Suche nach ähnlich klingenden Wörtern wird natürlich zurecht gestellt. Denn wenn mit dem Namen „Maier“ gesucht wird, so weiß man häufig nicht exakt, wie der Name tatsächlich geschrieben wird und falls man sich doch sicher ist, so könnte der Namen auch „falsch“ in der Datenbank angelegt worden sein. Somit darf die fehlertolerante Suche nicht an einer phonetischen Schreibvariante scheitern.
Technische Betrachtung der phonetischen Suche
Was verstehen wir technisch hinter einer phonetischen Suche? Im Grunde wird das Wort entsprechend normiert. Es handelt sich um eine Gleichsetzung auf einen Code und diese werden gegeneinander auf Identität geprüft. Wird beispielsweise mit Maier gesucht, so liefert die „Kölner Phonetik“ den Code „67“. In der Datenbank sind unter dem Code „67“ ebenfalls die Namen Meier, Meyer, Meir, natürlich auch Maier und sogar Meire abgelegt. Der fehlertolerante Vergleich ist somit einfach eine Prüfung auf Gleichheit bezüglich der Phonetik-Codes.
Bekannte phonetische Verfahren und einige Beispiele
Zu den bekanntesten phonetischen Verfahren zählen wir:
Soundex:
Der Soundex-Algorithmus ist für den Klang der englischen Sprache entwickelt worden. Er wurde bereits vor über 100 Jahren entwickelt und ist sehr einfach anzuwenden. Ein „Hash-Wert“ wird berechnet, indem man den ersten Buchstaben des Namens verwendet und die Konsonanten im Rest des Namens mit Hilfe einer einfachen Nachschlagetabelle in Ziffern umwandelt. Vokale und doppelt kodierte Werte werden gestrichen. Das Ergebnis wird auf vier Zeichen erweitert oder auf vier Zeichen gekürzt. Somit besitzen ähnliche Laute den gleichen Code. Der Vorteil liegt in einem sehr einfachen Algorithmus und einer festen Codelänge von vier Zeichen. Nachteile sind keine Fehlertoleranz im ersten Zeichen (Claus ist ungleich zu Klaus), sowie eine sehr hohe Toleranz bei langen Wörtern (folgendes wird gemäß Soundex phonetisch identisch: Frank, Frankfurt, Frankenthal, Frankenstein, …).
Kölner-Phonetik:
Die Kölner-Phonetik ist primär für die deutsche Sprachfamilie entwickelt worden und ist bereits ebenfalls über 50 Jahre alt. Sie bildet jeden Buchstaben eines Wortes auf eine Ziffer zwischen „0“ und „8“ ab, wobei der benachbarte Buchstabe die Codierung beeinflusst. Für den Wortanfang gibt es ebenfalls spezielle Regeln (Vokale am Wortanfang). Gleichklingende Buchstaben (Namen) erhalten somit den gleichen Zahlencode. Beispielsweise: Maier, Meier und Mayer werden alle auf den Code 67 umgewandelt. Im Gegensatz zum Soundex-Code ist die Länge des phonetischen Codes nach der Kölner Phonetik nicht beschränkt. Die Kölner Phonetik funktioniert mit deutschen Namen recht gut und findet nahezu alle phonetisch ähnlich klingenden Namen (oftmals auch zu viele Begriffe).
Metaphone:
Metaphone, 1990 von Lawrence Philips veröffentlicht, ist ein weiterer phonetischer Algorithmus, der frühere Systeme wie Soundex verbessert. Der Metaphone-Algorithmus ist deutlich komplizierter, da er spezielle Regeln für die Codierung von Zeichenketten und deren Position innerhalb eines Wortes berücksichtigt, sowie eine Abhängigkeit von Konsonantenkombinationen enthält. Der Metaphone-Algorithmus erzeugt Codes variabler Länge, die bei ähnlich klingenden Wörtern identisch sind. Eine erweiterte Version des Algorithmus, genannt Double Metaphone, geht sogar noch weiter, indem Regeln für die Behandlung von Schreibweisen und Aussprachen anderer Sprachen berücksichtigt werden.
| Name | Soundex | Kölner-Phonetik | Metaphone |
| Maier | M600 | 67 | MR |
| Mayer | M600 | 67 | MYR |
| Meier | M600 | 67 | MR |
| Meyer | M600 | 67 | MYR |
| Meir | M600 | 67 | MR |
| Meire | M600 | 67 | MR |
| Claus | C420 | 458 | KLS |
| Klaus | K420 | 458 | KLS |
| Frank | F652 | 3764 | FRNK |
| Frankenthal | F652 | 3764625 | FRNK |
| Frankfurt | F652 | 3764372 | FRNK |
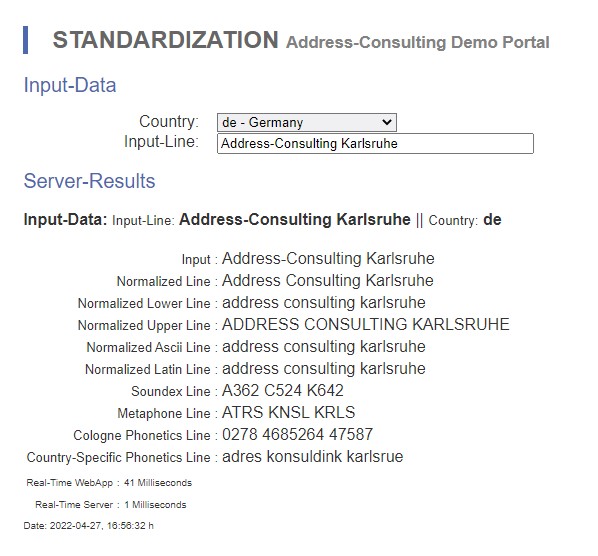
| Address Consulting | A362 C524 | 0278 4685264 | ATRS KNSL |
| Adress Konsulting | A362 K524 | 0278 4685264 | ATRS KNSL |
Grenzen der phonetischen Gleichsetzung
Natürlich haben die klassischen phonetischen Verfahren ihre Berechtigung. Doch für eine leistungsfähige fehlertolerante Datensuche ist eine Identitätsprüfung auf deren phonetischen Codes nicht ausreichend. Einerseits werden zu viele Kandidaten geliefert (hohe Rate an false-positives) und auf der anderen Seite werden viele Fehlerarten gar nicht erkannt (false-negatives). Auf diese Fehlerarten möchten wir hier noch kurz eingehen:
Landes- oder sprachspezifische Phonetik
Die phonetischen Algorithmen gehen kaum auf sprachspezifische Besonderheiten ein. Beispielsweise bleiben im französischen die Vokale oft stumm, hingegen im kroatischen jeder Vokal deutlich artikuliert wird.
Diakritische Zeichen
Diakritische Zeichen (franz. e, é, è, ê) werden von den Standardverfahren nicht ausreichend differenziert und daraus resultiert eine hohe false-positive Rate.
Andere Schriftzeichen
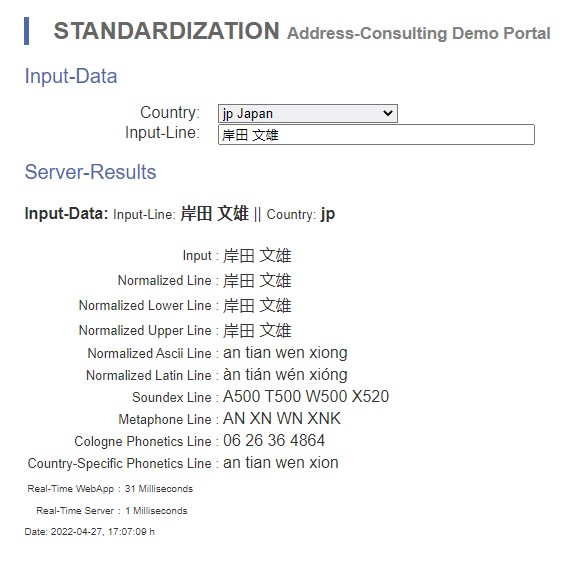
Die klassischen phonetischen Algorithmen sind nur für „wenige ASCII“ Zeichen definiert. Bereits Umlaute stellen ein Problem dar. Im internationalen Kontext finden wir viele andere Schriftzeichen . Allein in Japan werden vier verschiedene Schriften unterschieden (Romaji, Kanji, Hiragana, Katakana). Daneben dürfte für uns die chinesische Schrift die anspruchsvollste sein. Doch bereits in Europa haben wir unterschiedliche Schriften beispielsweise mit griechisch, georgisch und kyrillisch.
Insbesondere wenn Schriftzeichen transliteriert werden, ist eine Kombination mit einer phonetischen Normierung wichtig. Denn der kyrillische Name Ельцин kann als Yeltsin oder als Jeltzin geschrieben werden. Keine Schreibweise ist grundsätzlich falsch.
Fehlertoleranz auf Zeichenebene
Die Phonetik unterstützt lediglich ähnlich klingende Begriffe. Zeichenfehler in der Art von Tippfehlern oder Buchstabendreher werden nicht erkannt (Frank – Frak oder Frank – Frakn). Dieses Gebiet der Schreib-, Tippfehler und Variationen soll hier an dieser Stelle nicht weiter ausgeführt werden.
Abkürzungen und Synonyme
Ebenso nicht in die Kategorie der ähnlich klingenden Begriffe gehört die Fehlertoleranz bezüglich Abkürzungen (Ch. für Christian, Str. für Straße) und Synonyme (Andi – Andreas oder KFZ – Auto)
Fazit
Die phonetischen Verfahren haben ihre Berechtigung. Doch für einen leistungsstarken fehlertoleranten Abgleich oder Suche ist mehr notwendig. Zunächst muss sichergestellt werden, dass die Rate der false-positives gering bleibt und noch herausfordernder ist die Selektion der Datensätze mit Toleranzen aus Tippfehlern, landesspezifischen Besonderheiten.
Address-Consulting hat jahrelange Erfahrung in diesem Bereich mit nationalen, sowie internationalen Adressen. Darüber hinaus haben wir mehrere Projekte im Compliance-Umfeld durchgeführt, bei welchen Sanktionslisten verarbeitet werden.
Unsere Produkte berücksichtigen die Fehlertoleranzen zu einer landesspezifischen Phonetik, Abkürzungen, Synonyme, unterschiedlichen Schriftzeichen sowie Tippfehlern. Verschaffen Sie sich einen Einblick zu unserer Wortstandardisierung (Normierung) auf unserer Demo oder beispielsweise integriert in der Demo zum Address-Check.

Wir beraten und unterstützen Sie gerne bei Ihren Herausforderungen im Address-Management-Bereich. Sehr gerne können wir uns unverbindlich per Telefon bzw. E-Mail austauschen. Alternativ setzen wir auch gerne eine gemeinsame Videokonferenz auf. Sprechen Sie uns einfach an!
