Die klassische Aussage der Toolhersteller und unsere Antwort

Praktisch alle Software-Tools zur Dublettensuche haben umfangreiche Steuerungsparameter für die Toleranz der Verarbeitung. Wird eine tolerante Einstellung gewählt, so wird die Treffermenge größer und damit steigt die Wahrscheinlichkeit, dass der gewünschte Datensatz in der Trefferliste enthalten ist. Doch mit einer simplen Erhöhung der Toleranz werden neben den gewollten Datensätzen auch viele zusätzliche Datensätze in der Trefferliste landen. Die Kunst liegt darin, das Customizing so zu wählen, dass alle gewünschten Datensätze in der Suche enthalten sind, doch die Menge der ungewünschten Treffer entsprechend klein bleibt.
Aussagen der Tool-Anbieter
Wenn man den Aussagen der Tool-Hersteller glaubt, so liefern deren Suchsysteme genau die richtigen Treffer und kein relevanter Datensatz geht verloren. Man gewinnt den Eindruck, es werden ausschließlich die richtigen Datensätze angezeigt, alles läuft automatisch und dies alles „out of the box“. Sicherlich wird bei Nachfragen eingeräumt, dass es sich um ein „Fuzzy-System“ handelt, die Treffer einen Prozentwert für die Übereinstimmung erhalten und Auswahlen angeboten werden. Bei seriösen Anbietern wird auch auf die Parametervielfalt eingegangen, woran der Anwender erkennt, dass man für eine gute und passgenaue Trefferqualität etwas investieren muss.
Betrachten wir die „Google -Suche“, so wird jeder sagen: die Ergebnisse sind sehr gut und die relevanten Seiten sind fast immer mit dabei. Doch in der gesamten Treffermenge sind auch etliche ungewollte Treffer mit dabei. Wir sind es gewohnt, diese auszublenden und unseren Fokus auf die gewünschten Seiten zu lenken. Bei Namen und Adressen ist das nicht einfach. Für einen hohen Automatisierungsgrad muss die Rate der ungewünschten Treffer möglichst klein gewählt werden. Selbst Google bietet für seine Internet-Suchmaschine diverse Parameter für eine spezifischere Suche an. Denn es gibt Anwendungsfälle, bei welchen der Standard nicht ausreichend ist.
Etwas Theorie zu „true-“ und „false-postives bzw. „true-“ und „false-negatives“
Betrachten wir bei einer Suche mit einer bestimmten Eingabe einen bestimmten Treffer, so kann dieser in zwei Klassen gegliedert werden:

Treffer ist relevant
(„richtiger Treffer“, den will der Anwender haben)

Treffer ist nicht relevant
(„falscher Treffer“, den will der Anwender nicht haben)
Etwas abstrakter wird der folgende Gedankengang: Analysieren wir alle „nicht-Treffer“ bzgl. der Sucheingabe, können diese ebenfalls in zwei Klassen gegliedert werden:

Nicht-Treffer ist nicht relevant („richtiger Nicht-Treffer“, den will der Anwender auch nicht haben)

Nicht-Treffer ist relevant („falscher Nicht-Treffer“, den will der Anwender eigentlich haben)
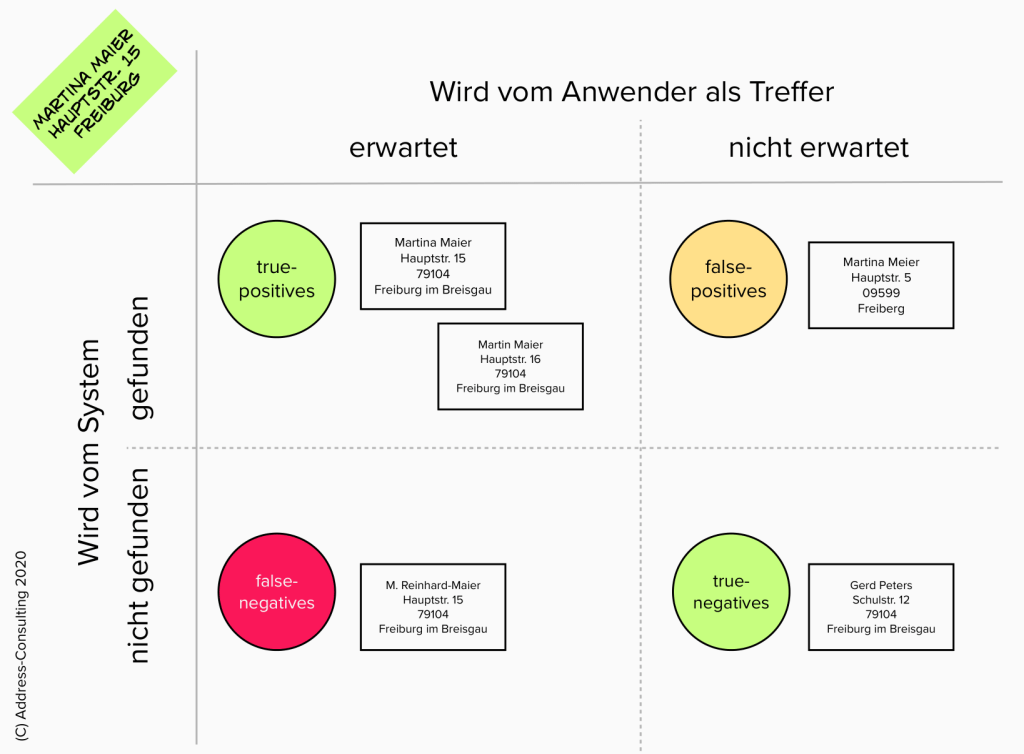
Mit diesen vier Fällen haben wir nun alle möglichen Varianten, welche ein bestimmter Datensatz bezüglich einer Sucheingabe annehmen kann. Wir bezeichnen diese vier relevanten Fälle wie folgt:
- true-positive: Der Treffer ist relevant und ist in der Trefferliste.
- false-positive: Der Treffer ist nicht relevant und wird dennoch in der Trefferliste angezeigt.
- true-negative: Der Treffer ist nicht relevant und ist auch nicht in der Trefferliste.
- false-negative: Der Treffer ist relevant und ist nicht in der Trefferliste.
Beispiel zu „true-“ und „false-positives“ bzw. „true-“ und „false-negatives“
Das Suchsystem soll folgende Datensätze im Bestand haben und gesucht wird mit:
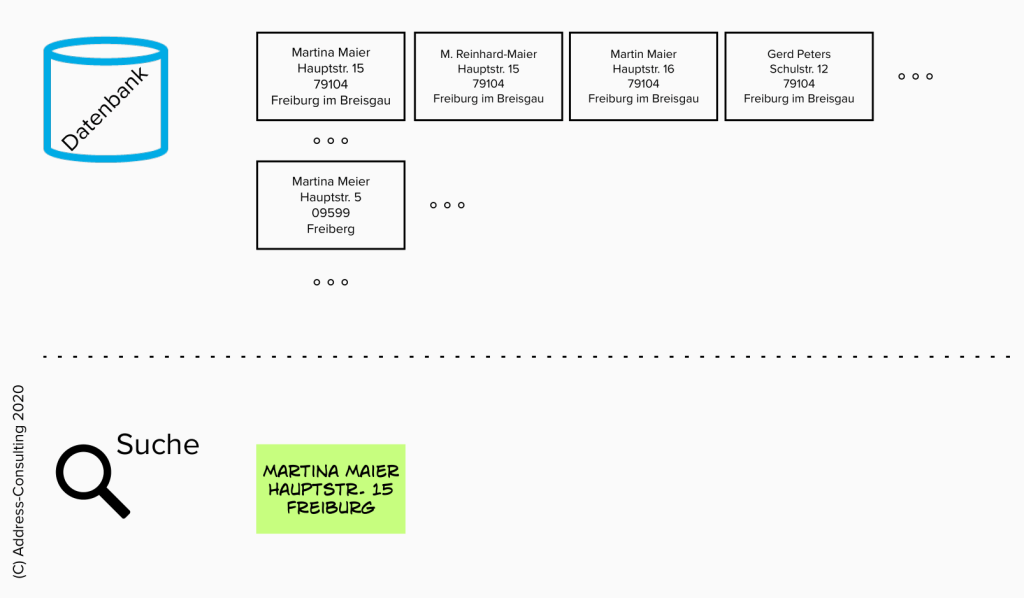
Dann liefert das System beispielsweise 3 Treffer:
- Martina Maier, Hauptstr. 15, 79104 Freiburg im Breisgau
(Volltreffer bzgl. der Suchargumente) - Martin Maier, Hauptstr. 16, 79104 Freiburg im Breisgau
(Toleranter Treffer mit hoher Übereinstimmung – vermutlich noch gewollt) - Martina Meier, Hauptstr. 5, 09599 Freiberg
(Datensatz hat Ähnlichkeiten bei allen Eingabeelementen, bezeichnet aber vermutlich nicht die gleiche Person)
Vermisst wird der Datensatz
- M. Reinhard-Maier, Hauptstr. 14, 79104 Freiburg im Breisgau
Dies ist eine Dublette zu Martina Maier, denn nach Heirat besitzt die Person einen Doppelnamen
Die ideale Welt
In einer idealen Welt würde die fehlertolerante Suchmaschine genau die „true-positives“ liefern und die Anzahl der „false-positives“ wäre Null. „Die Nicht-Treffer“ würden nur aus „true-negatives“ bestehen, d.h. die Anzahl der „false-negatives“ wäre ebenfalls Null.
Ziel einer guten Suchmaschine (gutes Customizing)
Das Ziel ist natürlich möglichst dicht am Idealfall zu sein (d.h. eine Suche liefert nur „true-positives“ und „true-negatives“). In der Praxis ist dies aus vielen Gründen nicht möglich (unterschiedliche Schreibweisen, Fehler in der Adressanlage, Fehler bei der Suche, Hörfehler, …). Gerade deshalb wird eine unscharfe (fehlertolerante) Suche angewendet, und somit muss das Ziel sein:
- „true-positives“ und „true-negative“ Rate möglichst hoch und
- „false-positive“ und „false-negative“ Rate möglichst klein halten.
Unsere Haltung
Die Stärken der Such-Systeme sind unterschiedlich und die Eignung ist anwendungsspezifisch. Mit jedem System können Dubletten gefunden werden. Doch auch bei jedem System muss für eine gute Einstellung des Trefferverhaltens ein beachtlicher Aufwand investiert werden.
Vielleicht ist für eine Vielzahl von Anwendungen die Standardinstallation eines geeigneten Suchsystems ausreichend. Wird jedoch ein möglichst hoher Automatisierungsgrad gewünscht, keine „false-negatives“ und kaum „false-positives“ und auch noch eine ansprechende Performance, so ist immer eine anwendungsspezifische Parametrierung notwendig. Unser „Best-Practice“ Ansatz ist:
- Im ersten Schritt führen wir mit den Anwendern einen Workshop durch. Bei diesem Workshop werden die Anforderungen an das System definiert (Mengengerüst, erste Datenanalyse, Anforderungen der Anwender (wie soll gesucht werden, Suchmuster …), Anforderungen an die Toleranz, sichere „nicht-Treffer“, überwiegend Consumer- oder Business-Daten, Erwartung an die Performance …).
- Im zweiten Schritt analysieren wir die Daten (verwendete Felder, Befüllungsgrad der Felder, Länderverteilung, Länderspezifika …).
- Auswahl eines geeigneten Suchsystems.
- Installation, Anlegen von geeigneten Testdatensätzen und Parametrierung (gemeinsam mit dem Anwender).
- Go-live.
- Nach dem Go-live meist noch eine Feedback-Schleife mit den Anwendern.
Nach unserer Erfahrung ist die Bewertung der „false-negative“ Datensätze schwierig, denn diese bleiben häufig unentdeckt.

Gerne führen wir mit Ihnen ein maßgeschneidertes Suchsystem ein oder unterstützen Sie beim Tuning Ihrer fehlertoleranten Suchmaschine. Beispielsweise erstellen wir bei einem gemeinsamen Workshop eine Bedarfs- und Schwachstellenanalyse und erarbeiten auf dieser Basis eine verbesserte Konfiguration. Sprechen sie uns einfach an.
Wir wünschen Ihnen eine besinnliche Adventszeit.
