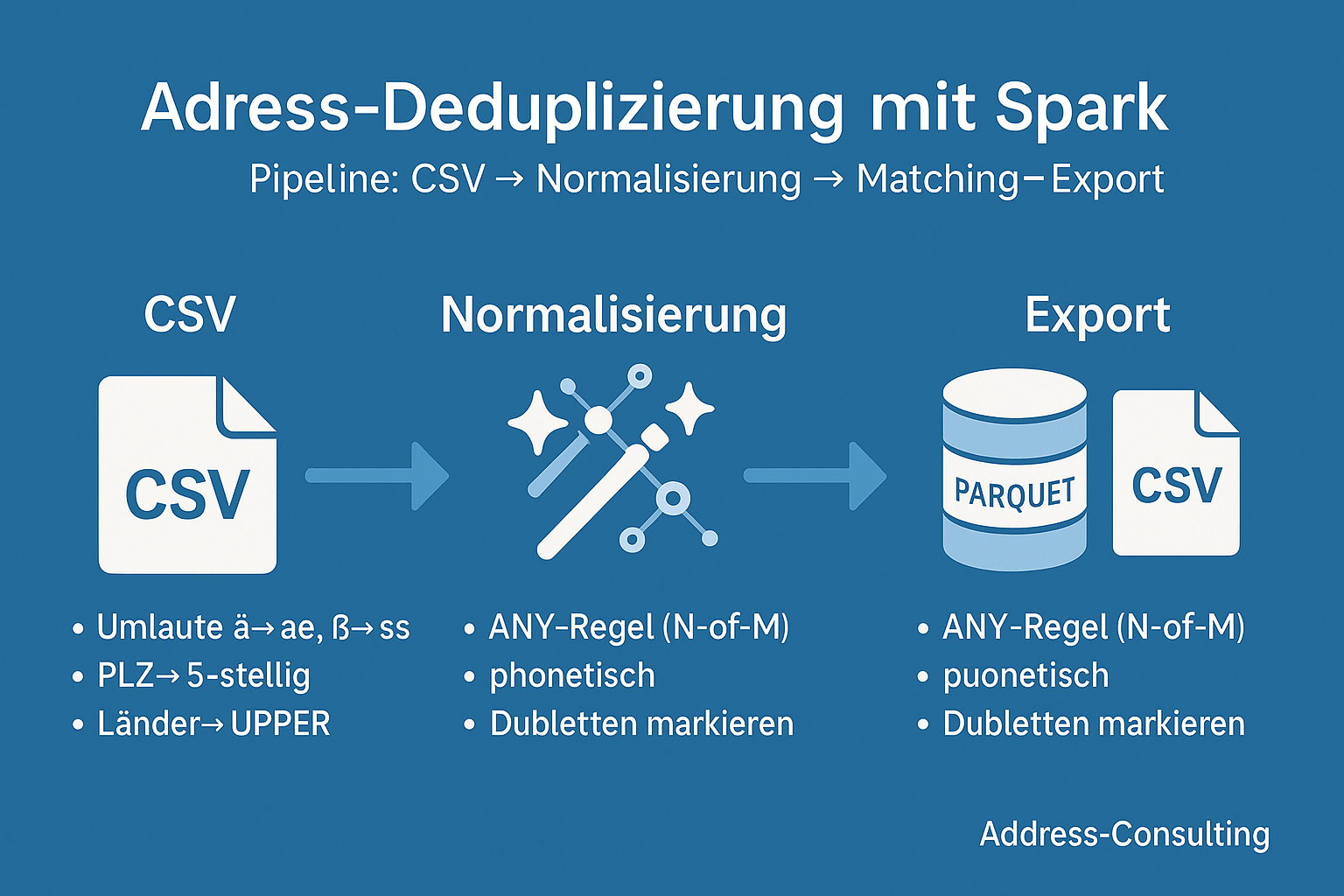
Von der Idee zum funktionierenden Big-Data-Projekt: Eine praxisnahe Reise durch die Dubletten-Erkennung mit PySpark. 1. Warum Dubletten-Erkennung? Kundendaten sind das Herzstück vieler Unternehmen. Doch in großen Beständen lauert ein Problem: Dubletten.Ob doppelt erfasste Adressen, fehlerhafte Schreibweisen oder unvollständige Datensätze – sie verfälschen Analysen, treiben Kosten in die Höhe und können sogar Compliance-Risiken nach sich ziehen.„Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise“ weiterlesen
-
Abonnieren
Abonniert
Du hast bereits ein WordPress.com-Konto? Melde dich jetzt an.
