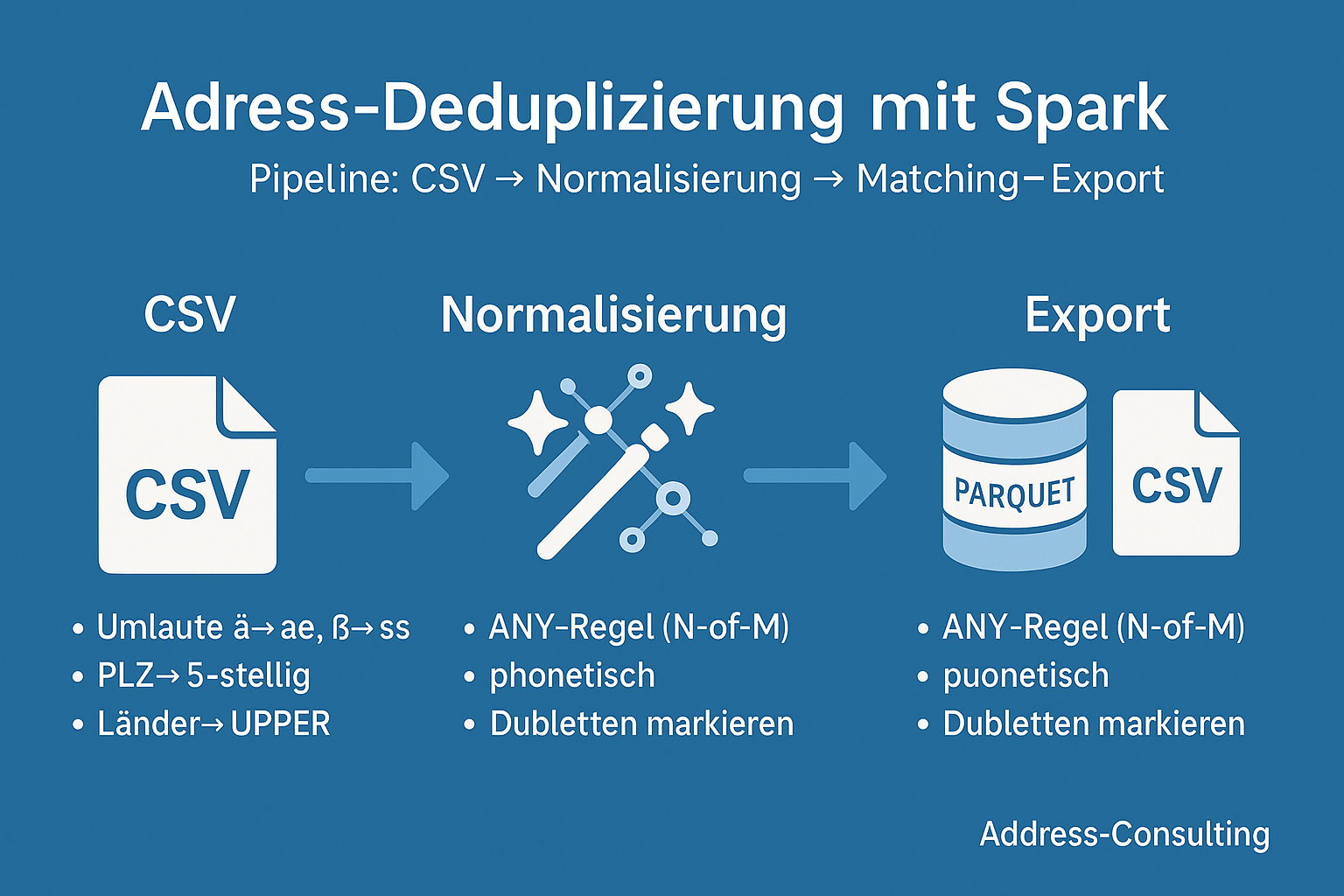
Von der Idee zum funktionierenden Big-Data-Projekt: Eine praxisnahe Reise durch die Dubletten-Erkennung mit PySpark. 1. Warum Dubletten-Erkennung? Kundendaten sind das Herzstück vieler Unternehmen. Doch in großen Beständen lauert ein Problem: Dubletten.Ob doppelt erfasste Adressen, fehlerhafte Schreibweisen oder unvollständige Datensätze – sie verfälschen Analysen, treiben Kosten in die Höhe und können sogar Compliance-Risiken nach sich ziehen.„Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise“ weiterlesen
Schlagwort-Archive:Data Management
Von MapReduce zu Apache Spark – die Evolution der Big-Data-Technologien

Apache Spark ist heute weit mehr als nur eine Big-Data-Engine: Von Customer Analytics über IoT bis hin zum Gesundheitswesen ermöglicht Spark Echtzeitanalysen in riesigen Datenmengen. Besonders wertvoll ist der Einsatz im Adressmanagement – Dublettenreduktion, Datenanreicherung und Aggregation schaffen die Grundlage für präzise Analysen und personalisierte Kundenansprache. So verbindet Spark Geschwindigkeit mit Datenqualität – und liefert die Basis für bessere Entscheidungen.
Big Data verstehen – und warum Datenqualität wichtiger ist als Datenmenge

Big Data – der Rohstoff des 21. Jahrhunderts?
Ja – aber nur, wenn die Qualität stimmt! Denn riesige Datenmengen allein bringen wenig, wenn Kundendaten fehlerhaft oder unvollständig sind.
In unserem aktuellen Blog zeigen wir, was hinter den 5 V von Big Data steckt – und warum Veracity (Wahrhaftigkeit) und Datenqualität entscheidend für echten Unternehmenserfolg sind.
Data Governance vs. Data Management
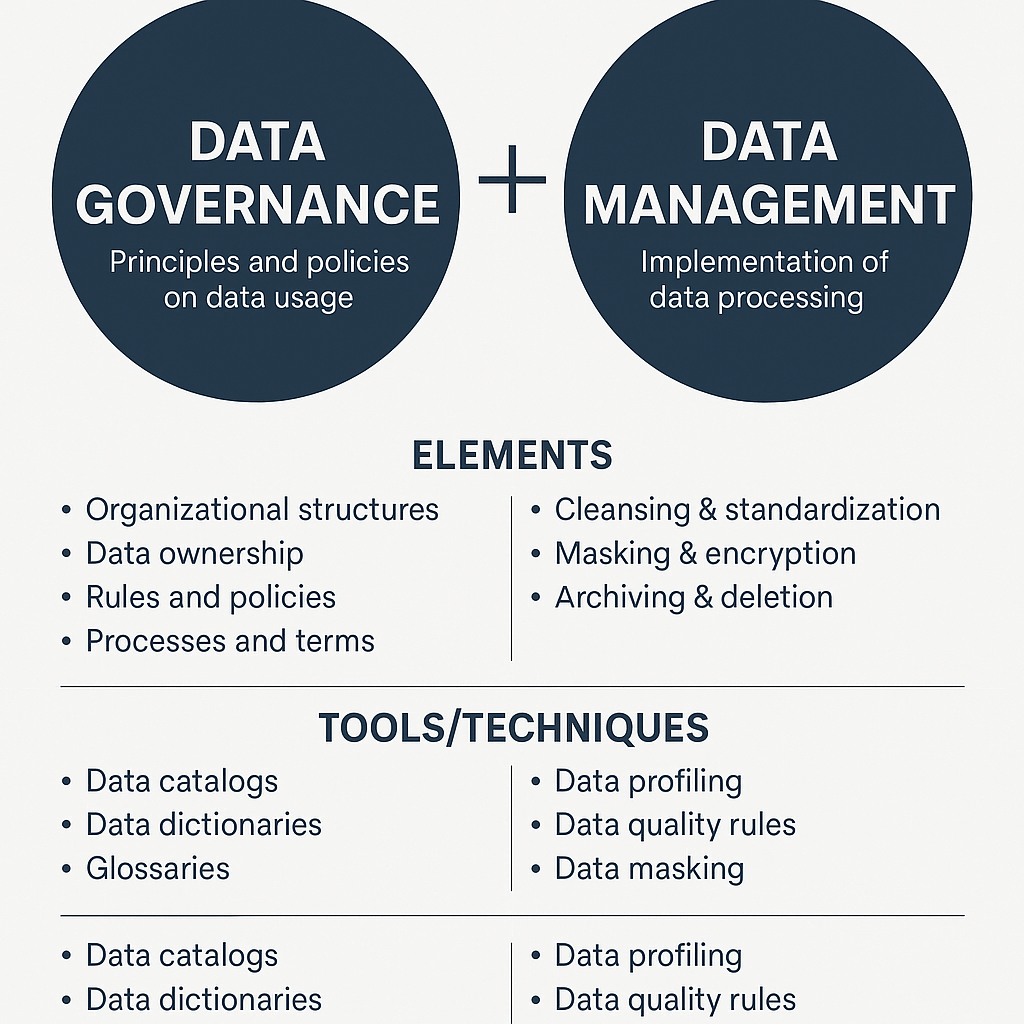
In einer zunehmend datengetriebenen Welt sind Begriffe wie Data Governance und Data Management in aller Munde – doch was genau unterscheidet die beiden? Und noch wichtiger: Wie greifen sie ineinander?
In diesem Beitrag werfen wir einen praxisnahen Blick auf die Rollen und Unterschiede von Data Governance und Data Management.
