
Databricks verbindet Data Engineering, Analytics und KI in einer Plattform. Wir zeigen, warum das Lakehouse-Konzept besonders bei Kundendaten neue Möglichkeiten eröffnet.
Schlagwort-Archive:Apache Spark
Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise
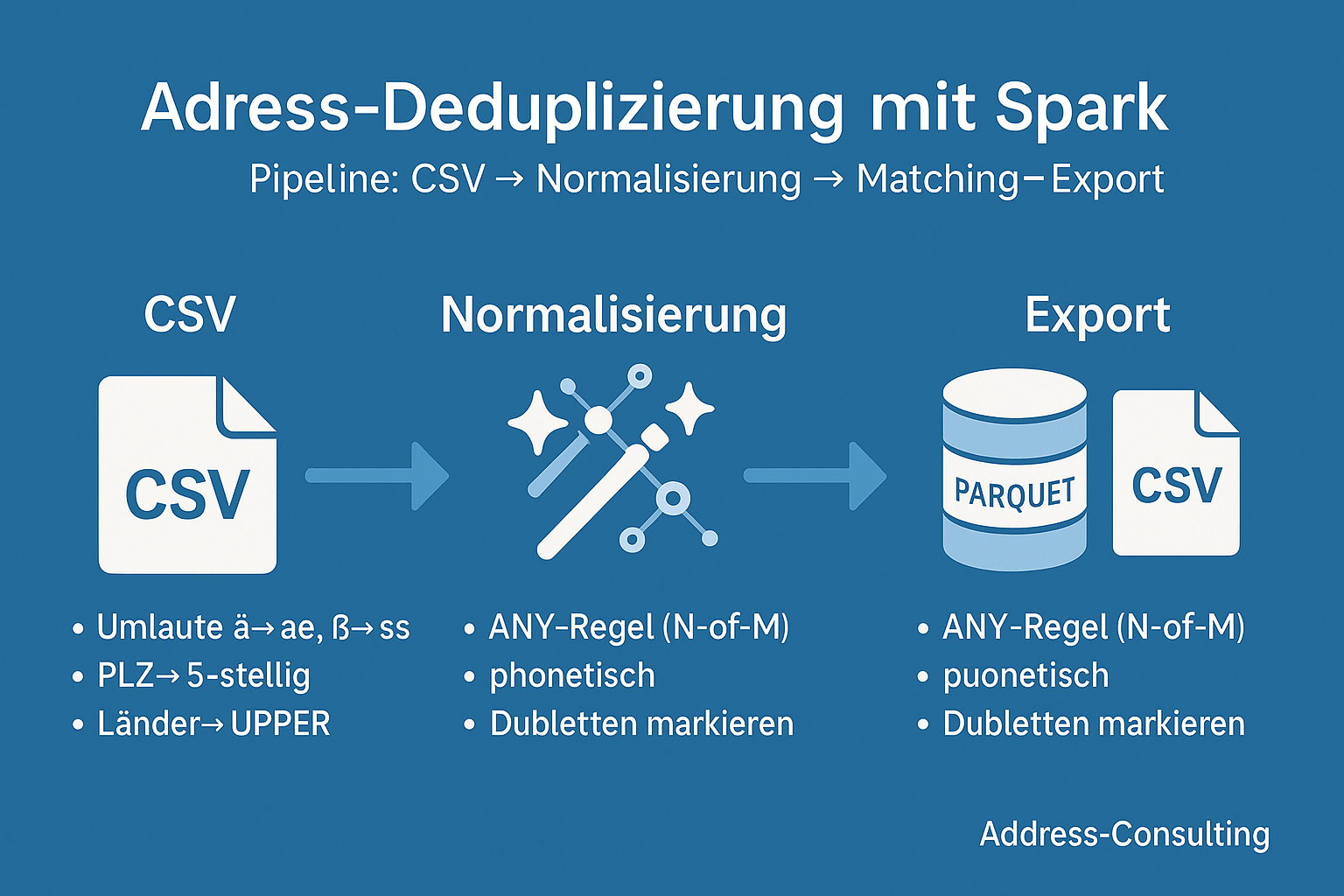
Von der Idee zum funktionierenden Big-Data-Projekt: Eine praxisnahe Reise durch die Dubletten-Erkennung mit PySpark. 1. Warum Dubletten-Erkennung? Kundendaten sind das Herzstück vieler Unternehmen. Doch in großen Beständen lauert ein Problem: Dubletten.Ob doppelt erfasste Adressen, fehlerhafte Schreibweisen oder unvollständige Datensätze – sie verfälschen Analysen, treiben Kosten in die Höhe und können sogar Compliance-Risiken nach sich ziehen.„Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise“ weiterlesen
Von MapReduce zu Apache Spark – die Evolution der Big-Data-Technologien

Apache Spark ist heute weit mehr als nur eine Big-Data-Engine: Von Customer Analytics über IoT bis hin zum Gesundheitswesen ermöglicht Spark Echtzeitanalysen in riesigen Datenmengen. Besonders wertvoll ist der Einsatz im Adressmanagement – Dublettenreduktion, Datenanreicherung und Aggregation schaffen die Grundlage für präzise Analysen und personalisierte Kundenansprache. So verbindet Spark Geschwindigkeit mit Datenqualität – und liefert die Basis für bessere Entscheidungen.
