
ETL oder ELT? Beide Ansätze integrieren Daten aus verschiedenen Quellen – unterscheiden sich aber in der Reihenfolge von Laden und Transformieren. Dieser Artikel zeigt dir die wichtigsten Unterschiede, typische Einsatzfälle und eine praktische Entscheidungshilfe für deinen Data Stack.
Autor-Archive:address-consulting
Data-Fabric-Lösungen für das Adressmanagement

Adressdaten sind die Basis vieler Geschäftsprozesse – und gleichzeitig eine der größten Herausforderungen im Datenmanagement.
Mit einer Data-Fabric-Architektur lassen sich verteilte Datenquellen intelligent verknüpfen, harmonisieren und kontrollieren.
In Kombination mit Data-Mesh-Prinzipien entsteht daraus eine Adressdaten-Fabric, die technische Integration und organisatorische Verantwortung verbindet – für mehr Datenqualität, Transparenz und Effizienz.
Data Warehouse vs. Data Lake – und warum das Lakehouse die Zukunft ist
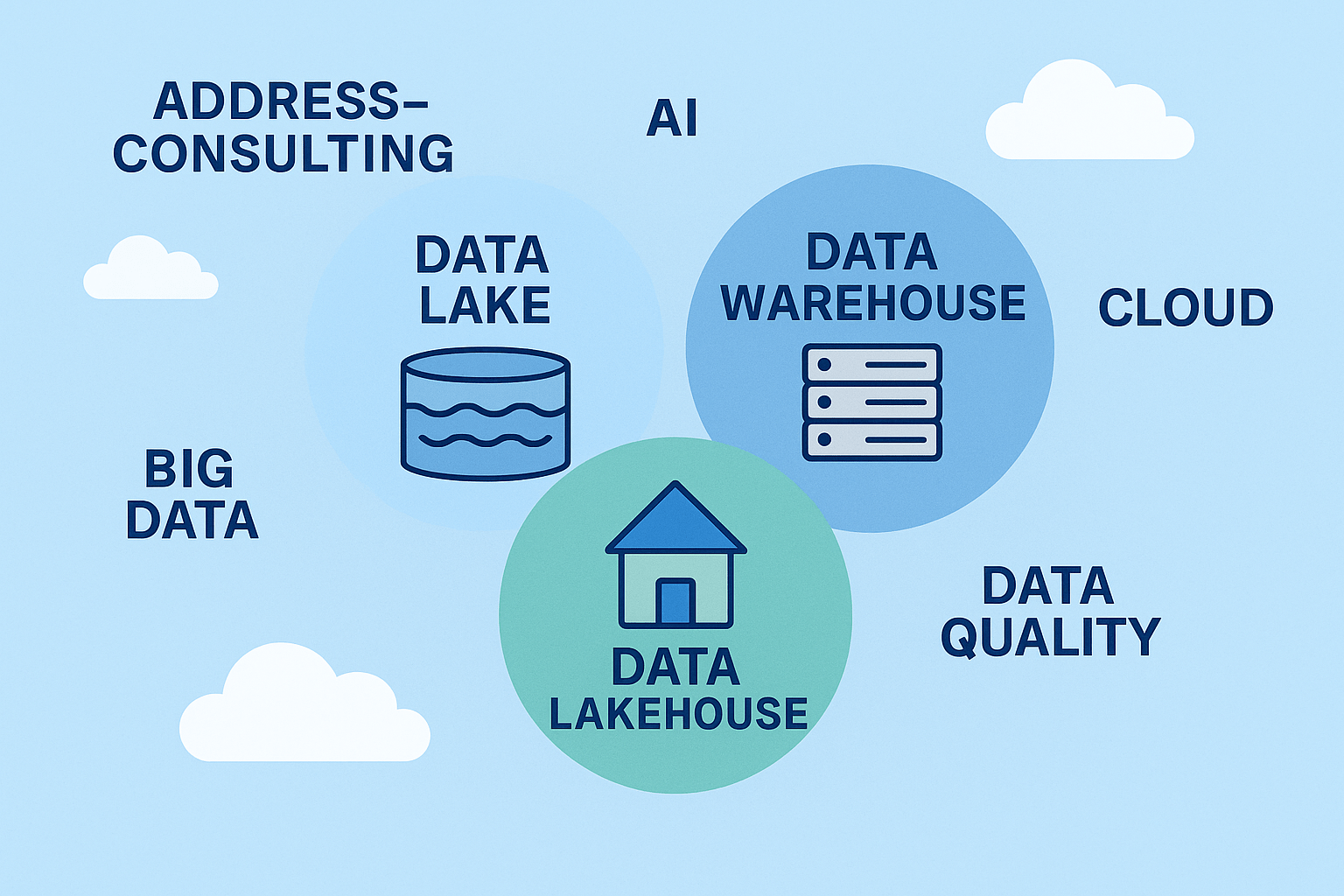
Das Data Warehouse steht für Struktur und Verlässlichkeit, der Data Lake für Offenheit und Skalierbarkeit.
Das Data Lakehouse verbindet beides: Datenqualität, Governance und Flexibilität in einer Plattform.
Unternehmen erhalten so eine einheitliche Basis für Business Intelligence, Machine Learning und KI.
Wir bei Address-Consulting unterstützen Sie dabei, den Weg vom klassischen Warehouse hin zum modernen Lakehouse zu gestalten – für bessere Daten, schnellere Analysen und mehr Wert aus Information.
Databricks: Erste Schritte mit Adressdaten

Databricks verbindet Data Engineering, Analytics und KI in einer Plattform. Wir zeigen, warum das Lakehouse-Konzept besonders bei Kundendaten neue Möglichkeiten eröffnet.
Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise
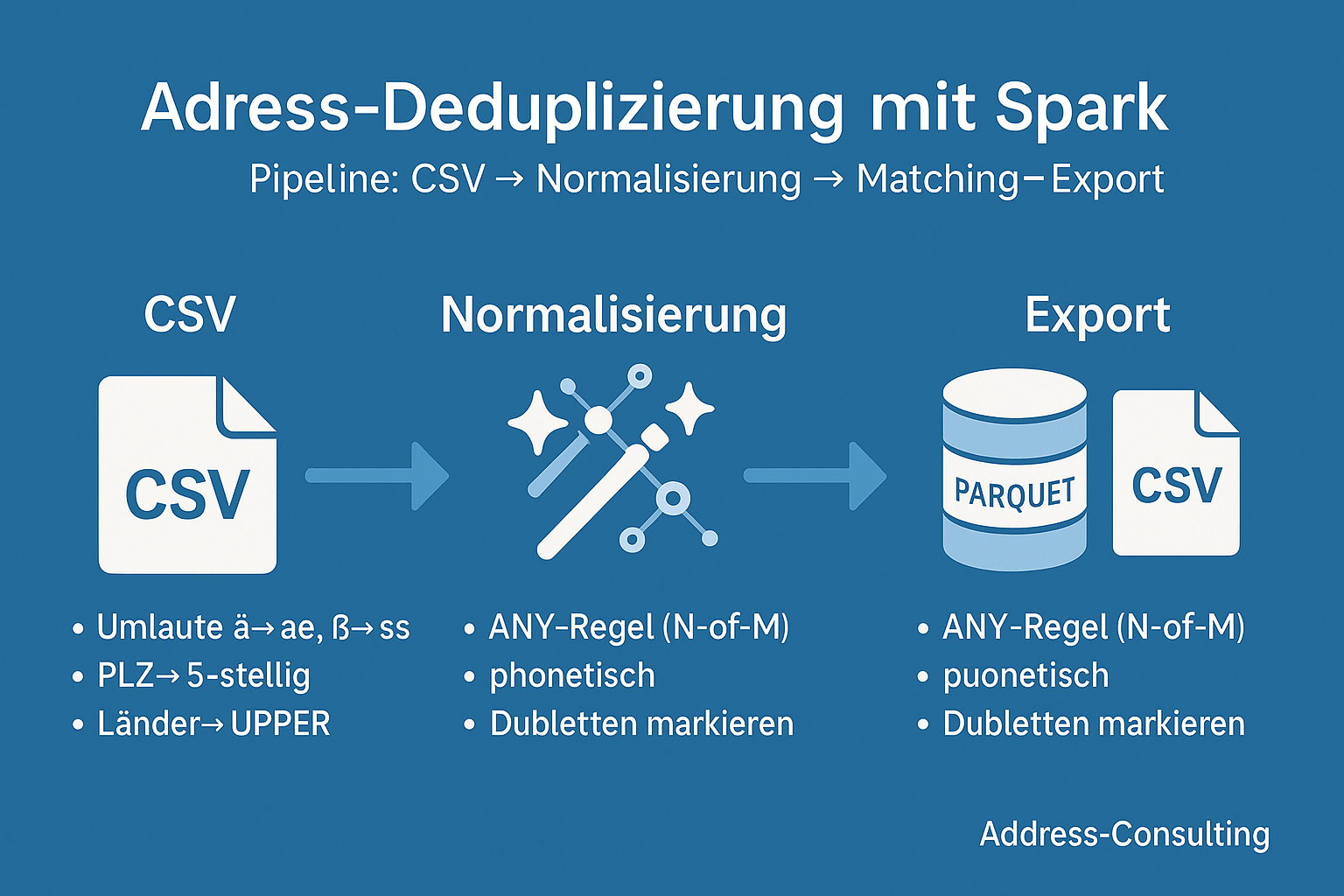
Von der Idee zum funktionierenden Big-Data-Projekt: Eine praxisnahe Reise durch die Dubletten-Erkennung mit PySpark. 1. Warum Dubletten-Erkennung? Kundendaten sind das Herzstück vieler Unternehmen. Doch in großen Beständen lauert ein Problem: Dubletten.Ob doppelt erfasste Adressen, fehlerhafte Schreibweisen oder unvollständige Datensätze – sie verfälschen Analysen, treiben Kosten in die Höhe und können sogar Compliance-Risiken nach sich ziehen.„Dubletten erkennen mit Apache Spark – eine Skizze unserer Projekt-Reise“ weiterlesen
Von MapReduce zu Apache Spark – die Evolution der Big-Data-Technologien

Apache Spark ist heute weit mehr als nur eine Big-Data-Engine: Von Customer Analytics über IoT bis hin zum Gesundheitswesen ermöglicht Spark Echtzeitanalysen in riesigen Datenmengen. Besonders wertvoll ist der Einsatz im Adressmanagement – Dublettenreduktion, Datenanreicherung und Aggregation schaffen die Grundlage für präzise Analysen und personalisierte Kundenansprache. So verbindet Spark Geschwindigkeit mit Datenqualität – und liefert die Basis für bessere Entscheidungen.
Big-Data-Technologien verstehen – MapReduce als Pionier der Datenverarbeitung
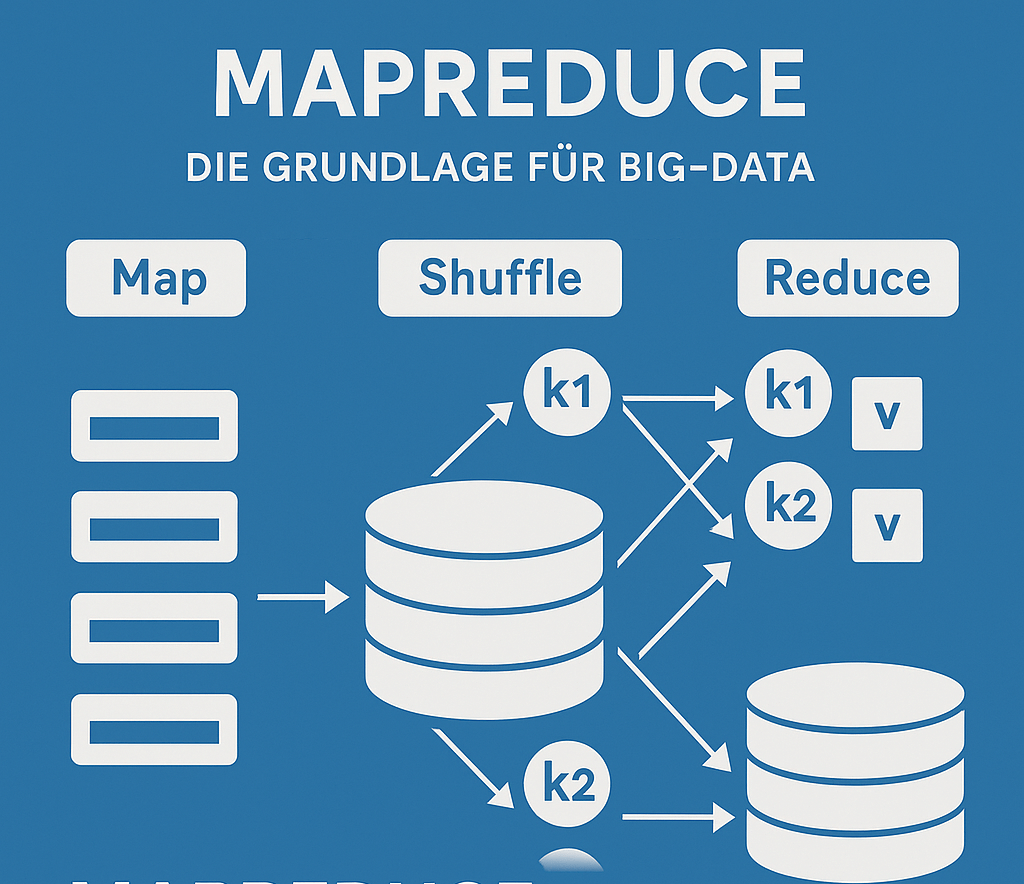
Wer Big Data verstehen will, kommt an MapReduce nicht vorbei. Das von Google entwickelte Programmiermodell ist die Basis vieler moderner Big-Data-Technologien und ermöglicht es, riesige Datenmengen parallel zu verarbeiten. Die drei Phasen – Map, Shuffle und Reduce – teilen komplexe Probleme in kleine, verteilbare Aufgaben auf und führen die Ergebnisse wieder zusammen. So wird aus einem Datenberg handhabbare Information – schnell, effizient und skalierbar.
Big Data verstehen – und warum Datenqualität wichtiger ist als Datenmenge

Big Data – der Rohstoff des 21. Jahrhunderts?
Ja – aber nur, wenn die Qualität stimmt! Denn riesige Datenmengen allein bringen wenig, wenn Kundendaten fehlerhaft oder unvollständig sind.
In unserem aktuellen Blog zeigen wir, was hinter den 5 V von Big Data steckt – und warum Veracity (Wahrhaftigkeit) und Datenqualität entscheidend für echten Unternehmenserfolg sind.
Data Governance vs. Data Management
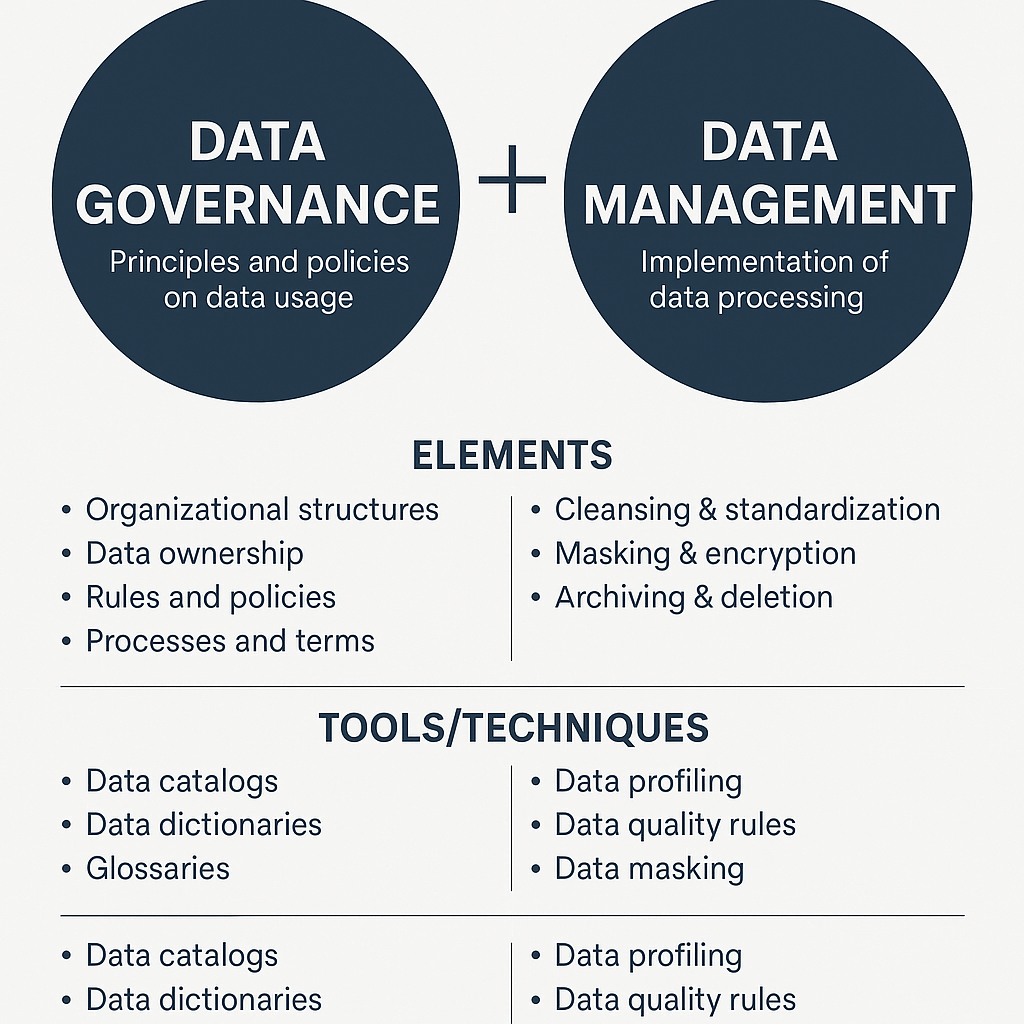
In einer zunehmend datengetriebenen Welt sind Begriffe wie Data Governance und Data Management in aller Munde – doch was genau unterscheidet die beiden? Und noch wichtiger: Wie greifen sie ineinander?
In diesem Beitrag werfen wir einen praxisnahen Blick auf die Rollen und Unterschiede von Data Governance und Data Management.
Data Governance

In Zeiten digitaler Transformation wird der verantwortungsvolle Umgang mit Daten zu einem zentralen Erfolgsfaktor für Organisationen. Ob Unternehmen, öffentliche Verwaltung oder gemeinnützige Organisation: Der strukturierte, transparente und verlässliche Umgang mit Daten bestimmt zunehmend über Effizienz, Rechtssicherheit und Wettbewerbsfähigkeit. Eine systematische Daten-Governance – also die Steuerung und Kontrolle der Datenverantwortung, -qualität und -nutzung – ist dafür„Data Governance“ weiterlesen
