Zwei Datenwelten, ein Ziel: Erkenntnis aus Daten
Unternehmen erzeugen mehr Daten denn je – strukturiert, semi-strukturiert, unstrukturiert. In Projekten bei Address-Consulting sehen wir: Das klassische Data Warehouse (DWH) liefert Governance und Verlässlichkeit; der Data Lake punktet mit Offenheit und Skalierbarkeit. Die entscheidende Bewegung der letzten Jahre: Lakehouse-Ansätze, die beides zusammenführen – inklusive ACID, Metadaten-Katalogen und einheitlicher Governance.
Unser Ziel in diesem Beitrag: klare Entscheidungsgrundlagen schaffen – wo DWH und Lake sinnvoll sind, warum Unternehmen oft beides benötigen und wie das Lakehouse die Lücke schließt.
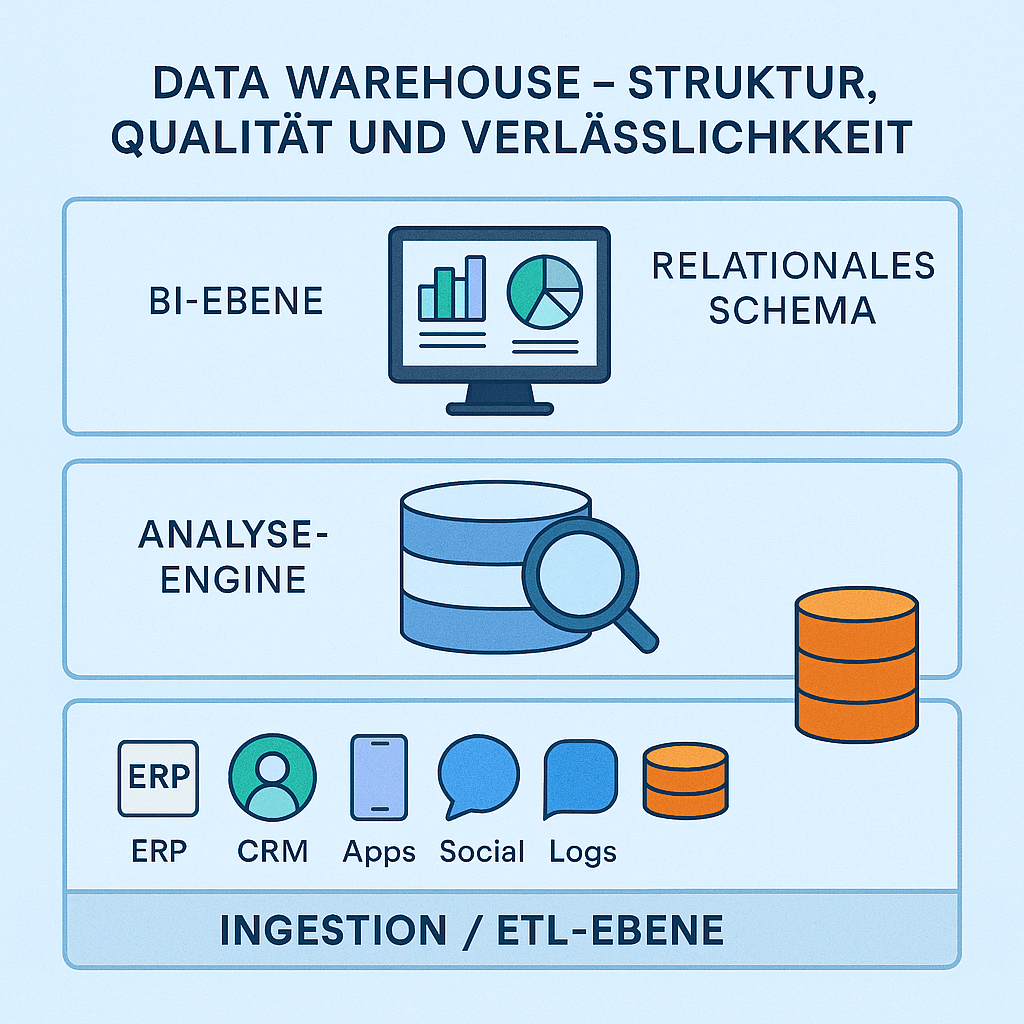
Data Warehouse – Struktur, Qualität und Verlässlichkeit
Ein Data Warehouse aggregiert Daten aus verteilten Quellen (ERP, CRM, Apps, Social, Logs) in einen konsistenten Speicher. Kernprinzip: Schema-on-Write – Daten werden beim Schreiben bereinigt, transformiert und in ein relationales Schema überführt (hohe Datenqualität, stabile Performance).
Architektur (3 Schichten):
- Ingestion/ETL-Ebene – Datenflüsse aus Quellsystemen, Validierung, Harmonisierung.
- Analyse-Engine – SQL/OLAP ermöglicht schnelle Abfragen und Aggregationen.
- BI-Ebene – Dashboards, Reports, Self-Service-Analytics.
Pluspunkte
- Verlässlichkeit & Konsistenz für KPIs, Reporting, Controlling
- ACID-Transaktionen, starke Governance, Auditfähigkeit
- Leistungsfähige SQL-Abfragen
Herausforderungen
- Aufwändige Modellierung & Änderungen, limitiert bei unstrukturierten Daten
- Höhere Kosten bei Kopplung von Compute & Storage (klassisch)
- Eher Batch-orientiert; KI/ML nur bedingt ideal
Begriffe aus der Praxis:
- Data Mart = DWH-Teilbereich für Fachdomänen (z. B. Marketing, HR).
- Hosting: on-prem, Cloud oder hybrid (zunehmend Cloud-nativ).
Data Lake – Offenheit, Skalierung und Innovation
Ein Data Lake speichert Rohdaten aller Typen kostengünstig (Cloud Object Storage wie S3/Blob/GCS). Prinzip: Schema-on-Read – das Schema wird erst beim Auslesen angewendet (maximale Flexibilität).
Architektur (modern):
- Storage entkoppelt von Compute → elastisch, kosteneffizient
- Verarbeitung via externe Engines (z. B. Apache Spark)
Pluspunkte
- Kostengünstig, nahezu unbegrenzt skalierbar
- Ideal für Data Science, ML, Explorationsanalysen, Backups & Archiv
- Aufnahme beliebiger Formate; ELT-freundlich
Herausforderungen
- Governance & Datenqualität müssen gezielt eingeführt werden (sonst Data Swamp)
- Business-Self-Service schwieriger ohne Ergänzungen (Katalog, Metadaten, Policies)
- Häufig separate Tools für Verarbeitung, Katalog & Qualität notwendig

Vier Kernunterschiede (kompakt)
| Merkmal | Data Warehouse | Data Lake |
|---|---|---|
| Datenstruktur | Verarbeitet, strukturiert | Roh, auch un-/semi-strukturiert |
| Schema | Schema-on-Write | Schema-on-Read |
| Ziel | Reporting, BI | ML/AI, Exploration |
| Nutzer | Business/BI | Data Scientists/Engineers |
| Governance | Stark | Flexibel, einzuführen |
| Kosten | Höher | Geringer |
| Verarbeitung | v. a. Batch | Batch + (externes) Streaming |
Kurz: Das Warehouse stabilisiert, der Lake befähigt.
Warum viele Architekturen beides brauchen – Data Fabric-Denken
Reale Datenlandschaften sind polyglott. Ein Data Lake dient oft als universelle Landezone; daraus versorgen wir Data Marts/DWHs für stabile Entscheidungsvorlagen. Für fortgeschrittene Analysen (ML/AI) arbeiten Teams häufig direkt auf Lake-Daten. Dieses Zusammenspiel nennen viele Data Fabric: Eine übergreifende, logisch zusammenhängende Datenarchitektur, die Silos auflöst und die richtigen Daten an die richtigen Nutzer bringt.
Lakehouse – Best of Both Worlds
Das Lakehouse kombiniert die Speicherflexibilität des Lakes mit der Analyse- und Governance-Stärke des DWH. Technisch gelingt das über offene Formate (Parquet) und Tabellen-Metadaten-Layer (z. B. Delta Lake, Apache Iceberg, Apache Hudi), die ACID, Time-Travel, Z-Ordering/Indexierung u. a. bereitstellen.
Typische Lakehouse-Merkmale
- Speicherung: kostengünstiger Object Storage (S3/Blob/GCS)
- Compute: entkoppelt, elastisch (MPP, Auto-Scaling)
- Abfrage: SQL/Ad-hoc für BI und anspruchsvolle Analytics
- ELT & Streaming: Batch + Echtzeit unterstützt
- Indexierung & Optimierung: u. a. Bloom-Filter, Datei-Skipping
- Offenheit: Parquet/Delta/Iceberg, breite Tool-Kompatibilität

Lakehouse – Schichtenmodell (integriert)
1) Aufnahmeschicht (Ingest)
- Batch & Streaming (CDC, Events)
- ETL oder ELT (zunehmend ELT: Roh laden, später transformieren)
2) Speicherschicht (Storage)
- Object Storage als zentrales, günstiges Fundament
3) Metadatenschicht (Catalog)
- Einheitlicher Metastore/Katalog (z. B. Unity Catalog)
- Schemadurchsetzung, Policy-Management, Lineage, Auditing
4) API/Access-Schicht
- Engines/Tools binden sich an (SQL, ML/AI, Notebooks, BI)
5) Nutzungsschicht (Consumption)
- BI/Reporting, Self-Service-Analytics
- Data Science/ML/AI, Operational Analytics
Damit entsteht eine Plattform für alle Workloads, ohne redundante Datenbewegungen.
Delta Tables, ACID & Time-Travel (Praxisnutzen)
Delta-Tabellen (oder Iceberg/Hudi) bringen ACID-Transaktionen in den Lake: konkurrierende Zugriffe bleiben konsistent, Upserts/Merges sind robust, Rollbacks/Versionierung (Time-Travel) ermöglichen reproduzierbare Analysen und sichere Fehlerkorrektur. Indexing & Statistics beschleunigen Abfragen, ohne „alles“ lesen zu müssen.
Unity Catalog & Governance (einheitlich statt punktuell)
Mit Unity Catalog (oder vergleichbaren Katalogen) zentralisieren wir:
- Zugriffskontrolle & Rollen, fein granular über Datenobjekte
- Auditing & Lineage (Wer nutzt was? Wie fließen Daten?)
- Data Sharing zwischen Workspaces/Partnern ohne Kopieren
So wird die Lakehouse-Offenheit betriebsreif – Governance wird zur Eigenschaft der Plattform, nicht zum nachträglichen Add-on.
Wo Lakehouse den Unterschied macht (Geschäftsnutzen)
- Eine Quelle der Wahrheit ohne Mehrfachhaltung und Synchronisationsaufwand
- Geringere TCO durch offene Formate, getrennte Skalierung und Cloud-Effekte (z. B. Spot Instances)
- Schnellere Time-to-Insight – BI auf frischen Daten, ML auf derselben Basis
- Besseres Team-Zusammenspiel: Engineers, Scientists, Analysten und Fachbereiche arbeiten konsistent auf einer Plattform
Drei-Wege-Vergleich (integriert)
| Merkmal | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Datenstruktur | Strukturiert (verarbeitet) | Roh; alle Formate | Roh & verarbeitet (vereint) |
| Schema | Write | Read | Read & Write |
| ACID | Ja | Nein | Ja |
| Governance | Hoch | Niedrig bis mittel | Hoch (zentral) |
| Skalierbarkeit | Mittel | Hoch | Hoch |
| Kosten | Höher | Niedrig | Niedrig |
| Workloads | BI/Reporting | ML/AI, Exploration | BI und ML/AI |
| ELT/ETL | Eher ETL | ELT-freundlich | ETL/ELT, Streaming |
| Nutzerkreis | Business/BI | DS/DE | Alle Teams |
| Beispiele | Snowflake, BigQuery, Synapse | S3/Blob/GCS + Spark | Databricks, Snowflake Unistore, Dremio, BigLake |
Typische Einsatzmuster in modernen Architekturen
- Data Lake als universelle Landezone (alle Rohdaten, beliebige Formate)
- DWH/Data Marts für Domänen (Reporting-optimiert, Self-Service)
- Lakehouse als Modernisierungspfad: schrittweise Integration, ohne bestehende Lakes/DWHs „wegzureißen“ – Koexistenz, dann Konsolidierung
Diese evolutionäre Modernisierung reduziert Risiko und fördert Akzeptanz in Teams.
ETL vs. ELT und Batch vs. Streaming
- ETL bleibt sinnvoll, wenn sensible/qualitätskritische Daten vor dem Persistieren konsolidiert werden müssen.
- ELT nutzt die Lakehouse-Power: Roh laden, im Zielsystem transformieren (performant, flexibel).
- Streaming (z. B. CDC, Events) ergänzt Batch-Pipelines – Lakehouses verarbeiten beides auf demselben Fundus.
Herausforderungen realistisch betrachten
- Einführungskomplexität: Governance-Modelle, Kataloge, Rollen & Prozesse sauber definieren.
- Kompetenzaufbau: Teams an offene Formate, Versionierung & neue Workflows (z. B. MLflow) heranführen.
- Betriebsdisziplin: Kosten via Auto-Stop, Job Compute, Sizing & Scheduling steuern; Data Quality (Checks, SLAs, Observability) konsequent verankern.
Kosten & Steuerung (kompakt)
Lakehouses profitieren vom verbrauchsbasierten Cloud-Modell: Compute getrennt von Storage, skalierbar und abschaltbar. Interaktive All-Purpose-Cluster sind teurer; Jobs-Compute/Serverless für wiederkehrende Pipelines oft deutlich günstiger. Governance & Observability verhindern kostspielige „Zombie-Jobs“.
Zielbild: Transparenz und Effizienz – Kosten folgen dem echten Nutzen.
Unser Fazit
Warehouse liefert Ordnung, Lake liefert Freiheit – das Lakehouse verbindet beides zu einer einheitlichen, offenen und governance-starken Plattform. Für uns ist es der logische nächste Schritt: weniger Silos, weniger Kopien, mehr Geschwindigkeit – und ein gemeinsamer Ort für BI, AI und ML.
Wir bei Address-Consulting begleiten Unternehmen auf genau diesem Weg – vom bestehenden Warehouse und Lake hin zum Lakehouse. Wenn Sie diese Modernisierung evaluieren oder ein Pilotprojekt starten möchten, sprechen Sie uns an.
Wie es bei uns weitergeht
Wir suchen aktiv einen Kunden/Anwender/Partner, der mit uns den produktiven Einsatz des Lakehouse-Ansatzes vertieft:
- Data-Quality-Pipelines & Observability,
- Domain-Data Marts auf Lakehouse-Basis,
- BI + ML auf einem gemeinsamen Datenfundament,
- Governance mit Unity Catalog inkl. Lineage & Data Sharing.
Lassen Sie uns gemeinsam zeigen, wie Lakehouse-Architekturen echte Mehrwerte schaffen – schneller, transparenter, wirtschaftlicher.
