Von der Idee zum funktionierenden Big-Data-Projekt: Eine praxisnahe Reise durch die Dubletten-Erkennung mit PySpark.
1. Warum Dubletten-Erkennung?
Kundendaten sind das Herzstück vieler Unternehmen. Doch in großen Beständen lauert ein Problem: Dubletten.
Ob doppelt erfasste Adressen, fehlerhafte Schreibweisen oder unvollständige Datensätze – sie verfälschen Analysen, treiben Kosten in die Höhe und können sogar Compliance-Risiken nach sich ziehen.
Bei kleineren Datenmengen helfen klassische Tools weiter. Doch was, wenn Millionen von Einträgen geprüft werden müssen? Genau hier kommt Apache Spark ins Spiel – ein Framework, das Daten parallelisiert und in riesigen Beständen performant verarbeiten kann.
Wir haben Spark genutzt, um eine skalierbare Lösung zur Dubletten-Erkennung zu entwickeln.
Im Folgenden stellen wir unser etwas minimalisiertes Praxisprojekt vor, das Spark zur Dublettenerkennung in großen Adressbeständen einsetzt.
2. Der Start: Python + PySpark und saubere Versionen
Die Reise beginnt oft klassisch: Eine virtuelle Umgebung (venv) muss eingerichtet werden: und PySpark wird installiert. Klingt simpel, bringt jedoch gleich eine erste Hürde mit sich:
python-Versionen: beispielsweise zeigte sich Version 3.7.7,pywar bereits bei 3.13 → zwei Interpreter parallel.- Lösung: eine saubere virtuelle Umgebung mit konsistenter Version.
py -3.13 -m venv .venv
call .\.venv\Scripts\activate
pip install pyspark pandas pyarrowLesson learned: Sauberes Setup spart später viel Ärger.
Ebenso die Versionsfalle mit Java und Spark
Beim ersten Start erlebt man gerne direkt einen Fehler:
UnsupportedClassVersionError (class file 61.0)Übersetzt: Spark und Java passten nicht zusammen.
Die Lösung: Installation eines aktuellen JDK 17/21, alte JRE-Versionen deinstallieren, JAVA_HOME und PATH korrekt setzen.
Klingt banal, ist aber eine typische Hürde im Umgang mit Spark (insbesondere für Spark-Neulinge).
3. Der erste Spark-Job
Endlich ein Erfolgsmoment: Ein minimales Script mit SparkSession und spark.range(5).show() lief ohne Fehler.
Die Spark-UI unter Port 4040 zeigte die Jobs live – ein tolles Feedback, dass Spark „at work“ ist.
4. Warum Spark fürs Adressmanagement – Vorteile auf einen Blick
Apache Spark zählt neben Hadoop und Flink zu den bekanntesten Plattformen für Cluster Computing und ist aktuell in vielen Projekten die erste Wahl. Durch die In-Memory-Verarbeitung beschleunigt Spark typische Schritte im Adressmanagement spürbar – von der Normalisierung über Fuzzy-Matching bis zur Aggregation.
- Tempo durch In-Memory: Transformationen und Prüfregeln laufen im Arbeitsspeicher – ideal für wiederholte Ketten wie „bereinigen → matchen → zusammenführen“.
- Einfach parallel & skalierbar: Millionen Datensätze werden über den Cluster verteilt verarbeitet – ohne Spezialhardware.
- Vertraute Sprachen & APIs: Java, Scala und PySpark (Python) decken unterschiedliche Teamprofile ab; der Einstieg bleibt schlank.
- Module für viele Fälle:
Spark SQL (DataFrames/SQL), Structured Streaming (nahe Echtzeit), MLlib (Ähnlichkeits-/ML-Verfahren), GraphX (Beziehungsanalysen).
Praxisnutzen im Adressmanagement: Spark eignet sich hervorragend für Dublettenreduktion, Standardisierung (ä→ae, ß→ss, PLZ/Land), Mehrspalten-Schlüssel sowie Anreicherung/Aggregation – schnell, nachvollziehbar und in großer Skalierung.
Kurz: Spark löst die üblichen Hürden – Effizienz, Parallelisierung, Skalierung – und bietet eine konsistente API. Im Anschluss zeigen wir unser kompaktes Beispielprojekt zur Dublettenerkennung in großen Adressbeständen.
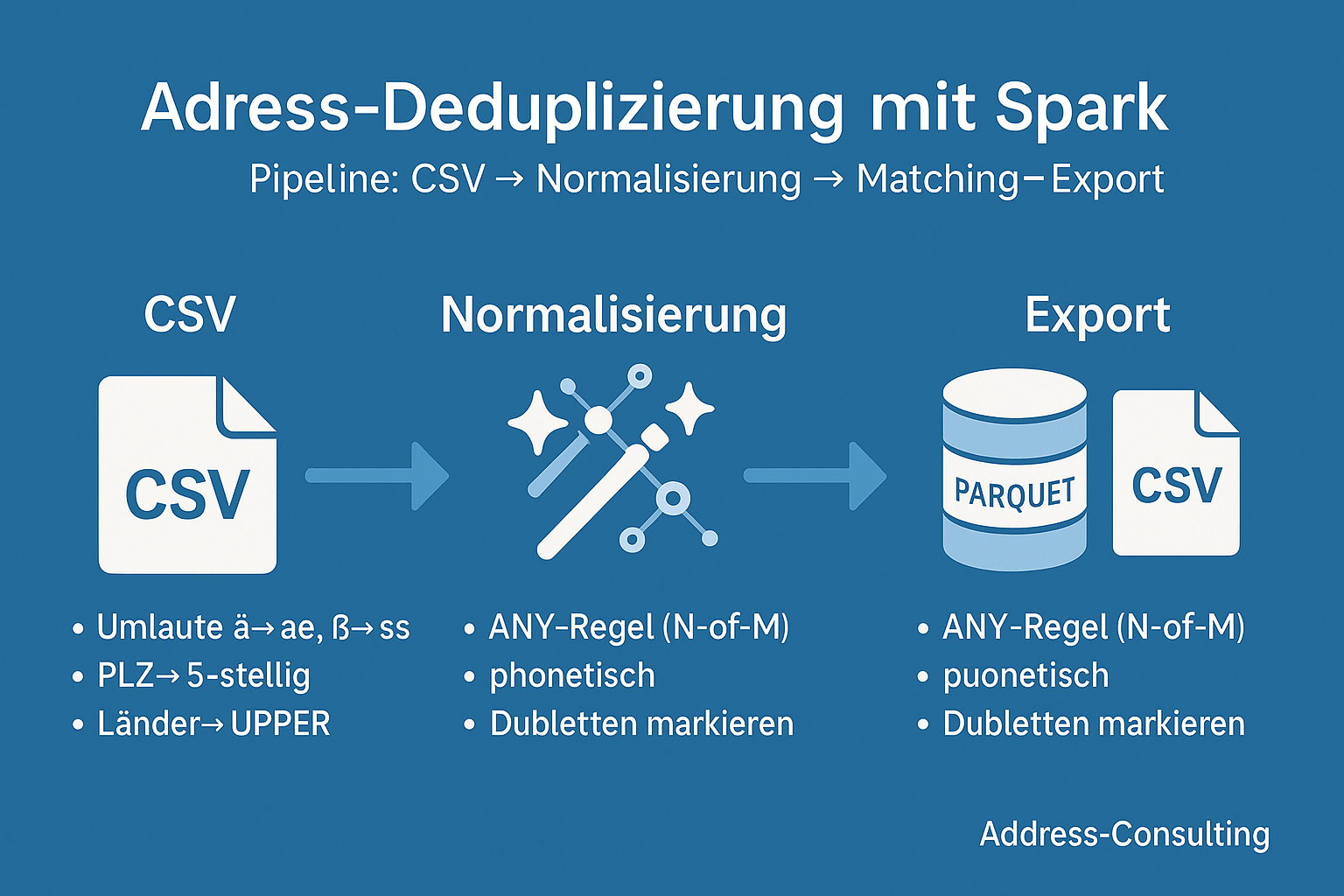
5. Orientierung: Main-Programm (kompakt)
CSV → Normalisieren → Dubletten markieren → Ergebnisse schreiben (Parquet/CSV)
Was der Abschnitt zeigt
- Start einer Spark-Session inkl. UI-Hinweis
- Einlesen von CSV (mit Header, Schema-Erkennung)
- Normalisierung nur der Key-Spalten (lower/trim/Whitespace, Umlaute/ß, PLZ, Länder)
- Markierung von Dubletten per Window-Funktionen (
_dup_count,_dup_rank,_is_duplicate) - Schreiben von Detail, „alle Dubletten“ und „nur echte Dubletten“
- Optional: Partitionierung (z. B. nach Kategorie), CSV/Parquet wählbar
Hinweis: Die ANY-Regel (mindestens N Spalten müssen matchen) und phonetische Verfahren (z. B. Kölner Phonetik, Soundex, Metaphone Line) sind als Erweiterung leicht anschließbar – für das Orientierungssnippet halten wir es bewusst geradlinig.
Das folgende kompakte Beispiel des main() zeigt die komplette Pipeline im Überblick: CSV einlesen → Schlüssel normalisieren → Dubletten markieren → Ergebnisse als Parquet/CSV schreiben.
from __future__ import annotations
import os
import shutil
from typing import List, Optional
from pyspark.sql import SparkSession, DataFrame, functions as F
from pyspark.sql.window import Window
from pyspark.sql.types import DecimalType
def main(
input_path: str = "data/*.csv",
out_base: str = "out/dups",
sep: str = ";",
encoding: str = "UTF-8",
dup_key: Optional[List[str]] = None,
normalize: bool = True,
zip_cols: Optional[List[str]] = None,
upper_cols: Optional[List[str]] = None,
partition_by_detail: Optional[List[str]] = None,
fmt: str = "parquet",
keep_ui: int = 0,
):
spark = build_spark()
ui = spark.sparkContext.uiWebUrl
print("Spark UI:", ui if ui else "(Spark not available)")
try:
# --- Read ---
df = read_csv(spark, input_path=input_path, sep=sep, encoding=encoding)
# --- Keys identify ---
dup_key = dup_key or (["id"] if "id" in df.columns else df.columns[:1])
print("Dup-Key:", dup_key)
# --- Normalize (only for keys; original remains untouched) ---
if normalize:
# Defaults for typical fields (you can overwrite/add via CLI)
default_zip_aliases = {"in_zip", "zip", "plz", "postleitzahl"}
default_upper_aliases = {"de", "country", "land", "iso2"}
zip_cols = set(zip_cols or []) | (default_zip_aliases & set(c.lower() for c in df.columns))
upper_cols = set(upper_cols or []) | (default_upper_aliases & set(c.lower() for c in df.columns))
df, key_norm = normalize_keys()
else:
key_norm = dup_key
print("Used (normalized) key columns:", key_norm)
# --- Mark duplicates ---
df = mark_duplicates(df, key_norm)
# --- preview & Statistics ---
print("\n=== Preview detail with flags ===")
df.select(*(dup_key + ["_dup_count", "_dup_rank", "_is_duplicate"])).show(10, truncate=False)
dup_total = df.where("_is_duplicate").count()
print(f"Duplicate lines (including first line per key): {dup_total}")
dup_only = df.where("_dup_rank > 1").count()
print(f"Real duplicate rows (without the first one per key): {dup_only}")
# --- Schreiben ---
detail_out = f"{out_base}/detail_with_flags"
dups_all_out = f"{out_base}/dups_all" # all lines with _is_duplicate = True (including the first key)
dups_only_out = f"{out_base}/dups_only" # only real duplicates (_dup_rank > 1)
summary_out = f"{out_base}/summary_by_key"
# Detail with flags (optional partitioning, e.g. by 'category')
detail_df = df
if partition_by_detail:
cols = [c for c in partition_by_detail if c in df.columns]
if cols:
detail_df = df.repartition(*cols)
write_df(detail_df, detail_out, fmt=fmt)
# all lines
write_df(df.where("_is_duplicate"), dups_all_out, fmt=fmt, coalesce1=(fmt == "csv"))
# only real duplicates (Rank > 1)
write_df(df.where("_dup_rank > 1"), dups_only_out, fmt=fmt, coalesce1=(fmt == "csv"))
# Summary per key
summary = (df.groupBy(*dup_key)
.agg(F.count(F.lit(1)).alias("rows"),
F.max("_dup_count").alias("dup_count_max"))
.where(F.col("rows") > 1)
.orderBy(F.col("rows").desc()))
write_df(summary, summary_out, fmt=fmt, coalesce1=True)
print("\n✅ Geschrieben nach:")
print(" -", detail_out)
print(" -", dups_all_out)
print(" -", dups_only_out)
print(" -", summary_out)
if keep_ui and ui:
import time as _time
print(f"Spark UI stays {keep_ui}s open: {ui}")
_time.sleep(keep_ui)
finally:
spark.stop()
Warum so? (kurz erläutert)
- Normalisierung nur für Schlüssel: Fachfelder bleiben unverändert, die Matching-Logik stützt sich auf
_norm-Spalten – transparent und reversibel. - Umlaute/ß/Whitespace/PLZ-Normierung/Land/phonetische oder regelbasierte Gleichsetzung: deckt 80 % typischer Adress-Abweichungen ab; erweiterbar um Synonymlisten oder phonetische Hashes.
- Window-Funktionen: klare Abgrenzung zwischen „erste Zeile je Gruppe“ und „echte Dublette“.
- Parquet/CSV: Maschine (Parquet) und Mensch (CSV) bekommen ihr optimales Format.
So führst du das Beispiel aus:
# venv aktivieren, Pakete installieren (falls noch nicht geschehen)
# Windows (Beispiel):
py -3.13 -m venv .venv
.\.venv\Scripts\activate
pip install pyspark pandas pyarrow
# Spark-Job starten
python main.py6. CSV zu Parquet: der Windows-Klassiker
Beim Import größerer CSV-Dateien tauchten neue Probleme auf:HADOOP_HOME and hadoop.home.dir are unset
Unter Windows braucht Spark für manche Operationen das Hilfsprogramm winutils.exe und eine hadoop.dll. Wir haben diese ins Projekt gelegt und mit Umgebungsvariablen referenziert:
set "HADOOP_HOME=%~dp0hadoop-3.4.1"
set "PATH=%HADOOP_HOME%\bin;%PATH%"So konnten wir CSV-Dateien zuverlässig in Parquet konvertieren.
👉 Was ist Parquet?
Parquet ist ein spaltenorientiertes Speicherformat für Big Data. Anders als CSV (zeilenorientiert) speichert Parquet spaltenweise – mit drei großen Vorteilen:
- Effizienz: Es werden nur benötigte Spalten gelesen → schnellere Abfragen.
- Kompaktheit: Starke Kompression reduziert Speicherplatz.
- Kompatibilität: Nahtlos in Spark, Hadoop, Hive und Data-Lake-Umgebungen nutzbar.
Für uns bedeutete das: weniger Speicher, schnellere Pipelines, bessere Handhabbarkeit großer Bestände.
7. Dubletten-Markierung: Der Kern der Lösung
Im nächsten Schritt ging es ans Eingemachte: Duplikate identifizieren.
Wir haben für jeden Datensatz Attribute ergänzt:
_dup_count(Anzahl der Vorkommen)_is_duplicate(Flag)_dup_rank(Reihenfolge in der Dublettengruppe)
Beispiel:
„Anna Meier“ ist mehrfach angelegt – einmal „Hauptstraße 1, 12345 Berlin“, einmal „Hauptstr. 1, 12345 Berlin“, ein drittes Mal ohne PLZ.
Mit den Markierungen wird sofort sichtbar: drei Datensätze derselben Person, fachlich zusammengehörig.
Wichtig: Markieren bedeutet nicht Löschen. Erst die Auswertung entscheidet (z. B. „behalte den vollständigsten oder aktuellsten Datensatz“).
8. Normalisierung: Äpfel mit Äpfeln vergleichen
Adressen und Namen sind oft voller Varianten – ohne Normalisierung erkennt kein System verlässlich Dubletten:
- Schreibweisen: „Hauptstraße 1“ vs. „Hauptstr. 1“
- Länder: „DE“ vs. „Deutschland“
- Umlaute: „ä/ö/ü“ → „ae/oe/ue“
- Eszett: „ß“ → „ss“
- Initialen: „F Rotzinger“ vs. „Frank Rotzinger“
- Synonyme/Kosenamen: „Josef“ ↔ „Sepp“, „Andreas“ ↔ „Andy“
- Phonetisch ähnlich: „Stephan“ ↔ „Stefan“
Unsere Normalisierung in Spark:
- Texte vereinheitlichen (lower/trim/Whitespace komprimieren)
- PLZ auf 5 Stellen „lpad“en, nur Ziffern
- Länder
upper() - Regeln für Umlaute/ß/Abkürzungen
- optional: phonetische Hashes (z. B. Kölner Phonetik, Soundex) als zusätzliche Matching-Spalten
So wurden auch Fälle wie „Stefan/Stephan“ oder „Andy/Andreas“ erkennbar.
Auf unserer Demoseite sind hier ein paar Algorithmen gegenüber gestellt:
https://demo.address-cloud.com/AddrConsDemo/standardization.html
9. Die ANY-Regel: Flexibilität zählt
Nicht immer müssen alle Spalten exakt übereinstimmen.
Wir haben eine Regel eingeführt: mindestens N Spalten müssen matchen (z. B. Name + Straße, auch wenn PLZ abweicht).
Ergebnis: versteckte Dubletten (Umzug, Tippfehler, Teil-Initialen) kommen zuverlässig ans Licht, ohne zu viele False Positives zu erzeugen.
10. Von Parquet zu CSV: für Menschen lesbar
Spark liebt Parquet – aber viele Fachbereiche arbeiten mit CSV (z. B. zur manuellen Prüfung oder für Excel-Reviews).
Unser Helfer-Script fasst Parquet-Ausgaben zusammen und erzeugt eine Excel-freundliche CSV – kleiner Schritt mit großer Wirkung im Alltag.
11. Paare bilden: A ↔ B
Zur Validierung erzeugen wir Paare: Jeder potenzielle Match erhält seinen Partner, inkl. der Spalten, die gematcht haben.
Das erleichtert die Nachvollziehbarkeit („warum wurde das gematcht?“) und hilft beim Feintuning der Regeln.
12. Ergebnis: Skalierbare Dubletten-Erkennung
Am Ende steht eine robuste Spark-Pipeline für Adressdaten:
- Import großer CSV-Bestände
- Speicherung in Parquet
- Normalisierung (Umlaute, ß→ss, PLZ, Länder, Whitespace)
- Dubletten-Erkennung nach flexiblen Regeln (ANY/N-of-M)
- Paardarstellung zur Review
- Export in Parquet und CSV
Skalierbar, schnell, nachvollziehbar – geeignet für Millionen Datensätze.
13. Lessons Learned
- Sauberes Setup (Python, Java, Hadoop-Client) ist die halbe Miete.
- Spark auf Windows braucht
winutils/HADOOP_HOMEund sauberes PATH-Handling. - Normalisierung ist Pflicht – sonst bleiben viele Dubletten unerkannt.
- Regeln flexibel gestalten (z. B. ANY/N-of-M, phonetische Ähnlichkeit).
- Früh an den Export denken – Parquet für die Maschine, CSV für den Menschen.
Unser Fazit
Unsere Reise zeigt: Spark ist kein Selbstläufer – aber ein mächtiges Werkzeug.
Mit In-Memory-Verarbeitung, starker Parallelisierung und den passenden Modulen (SQL, Streaming, MLlib) wird Adressmanagement auf Big-Data-Niveau praktikabel: Dubletten reduzieren, Daten anreichern, Aggregationen bilden – schnell und skalierbar.
Gerade für Unternehmen mit großen Kunden- oder Adressbeständen ist das ein echter Gamechanger – in Bezug auf Datenqualität, Effizienz und Compliance.
👉 Mehr dazu, wie Address-Consulting Unternehmen bei Data Governance, Datenqualität und Big-Data-Projekten unterstützt, finden Sie hier:
https://address-consulting.com/
