Von Datenqualität zur Datenverarbeitung: Wie MapReduce die Grundlage für moderne Big-Data-Systeme legte
1. Einleitung: Vom Datenberg zur Datenverarbeitung
Im letzten Blogbeitrag haben wir uns angesehen, warum Datenqualität entscheidend ist, damit Big Data nicht zum Datenmüll verkommt. Doch selbst wenn die Daten korrekt, sauber und konsistent sind, bleibt eine zentrale Frage:
Wie lassen sich Terabytes oder sogar Petabytes an Informationen effizient verarbeiten?
Genau hier setzt MapReduce an – ein Programmiermodell, das einst den Durchbruch für Big-Data-Technologien markierte. Entwickelt von Google und später durch das Apache-Hadoop-Ökosystem populär gemacht, hat MapReduce die Art und Weise verändert, wie Unternehmen mit gigantischen Datenmengen umgehen.
In diesem Artikel werfen wir einen genauen Blick auf MapReduce: seine Funktionsweise, Vorteile, Grenzen – und warum es auch heute noch wichtig ist, diese Basistechnologie zu verstehen.
2. Was ist MapReduce?
MapReduce ist ein Framework für die verteilte Verarbeitung großer Datenmengen auf Clustern aus vielen, oft kostengünstigen, Servern.
- Entwickelt von Google (bereits 2004): Das Paper „MapReduce: Simplified Data Processing on Large Clusters“ beschrieb erstmals dieses Modell.
- Open-Source-Umsetzung in Hadoop: Die Apache-Community übernahm die Idee und baute sie in das Hadoop-Framework ein, das bis heute weit verbreitet ist.
Die Grundidee ist einfach, aber mächtig:
- Daten werden auf viele Maschinen verteilt.
- Jede Maschine bearbeitet einen Teil der Aufgabe („Map“).
- Anschließend werden die Ergebnisse zusammengeführt und verdichtet („Reduce“).
Damit wurde es möglich, gigantische Datenmengen parallel und fehlertolerant zu verarbeiten – ohne Supercomputer, sondern mit Clustern aus Standard-Hardware.
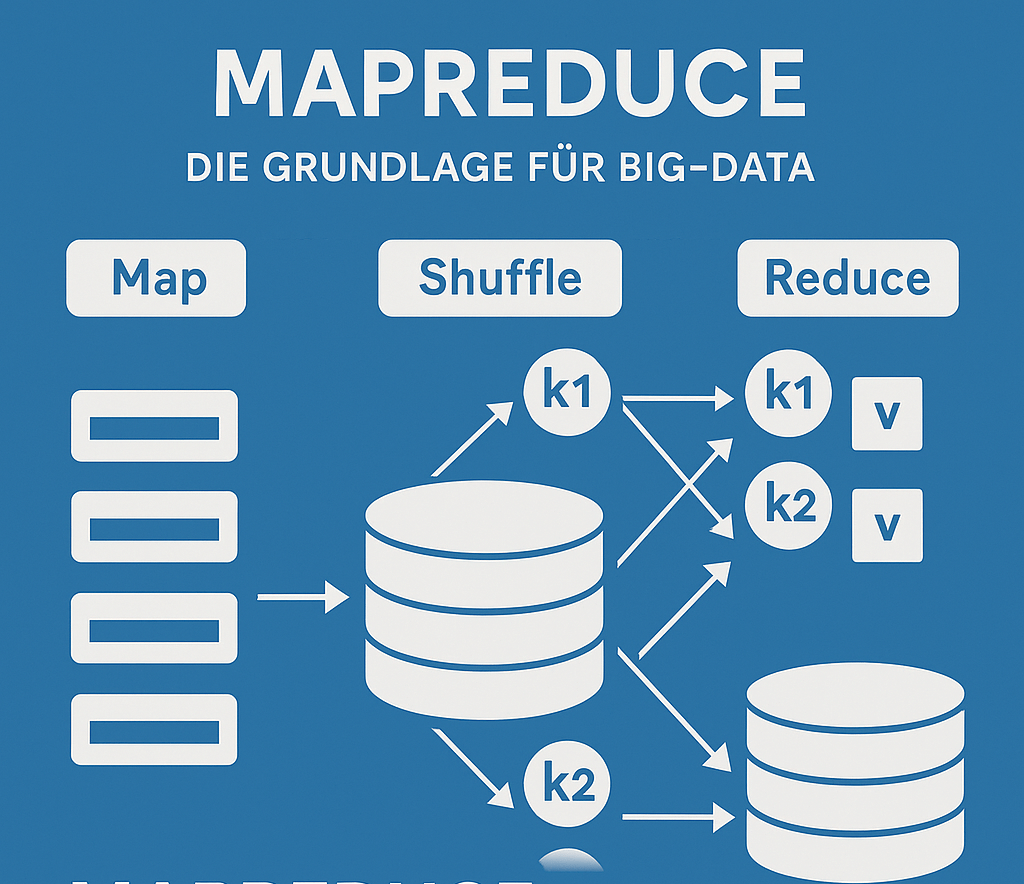
3. Funktionsweise von MapReduce
🔹 Die drei Phasen
- Map-Phase
- Große Datenmengen werden in kleine Teile zerlegt.
- Jeder Teil wird auf einem Clusterknoten verarbeitet.
- Ergebnis: Schlüssel-Wert-Paare (Key-Value-Pairs).
("Wort", 1) - Shuffle & Sort
- Die erzeugten Key-Value-Paare werden sortiert und nach Schlüsseln gruppiert.
- Alle Einträge zu einem Schlüssel landen zusammen.
- Reduce-Phase
- Die gruppierten Daten werden aggregiert.
- Endergebnis entsteht.
("Big Data", 53)
🔹 Ein einfaches Beispiel: Wortzählung
Die „Word Count“-Aufgabe ist das klassische MapReduce-Beispiel:
- Input: Sammlung von Dokumenten.
- Map: Jedes Wort wird mit dem Wert
1ausgegeben. - Shuffle: Alle gleichen Wörter werden gesammelt.
- Reduce: Die Werte werden addiert → Gesamtanzahl pro Wort.
Dieses einfache Prinzip lässt sich auf Millionen Datensätze skalieren – von Logdateien über Transaktionsdaten bis hin zu Social-Media-Posts.
4. Vorteile von MapReduce
MapReduce war die erste Technologie, die Big-Data-Verarbeitung wirklich praktikabel machte. Die wichtigsten Vorteile:
- Skalierbarkeit: MapReduce kann Daten im Petabyte-Bereich verarbeiten, indem es Rechenlast auf Tausende von Servern verteilt.
- Parallelisierung: Aufgaben werden automatisch parallelisiert – Programmierer müssen nicht selbst komplexe Multi-Thread- oder Parallelprogramme schreiben.
- Fehlertoleranz: Fällt ein Server aus, werden die Aufgaben einfach neu gestartet – ohne dass der Gesamtprozess stoppt.
- Kosteneffizienz: Statt teurer Spezialhardware werden günstige „Commodity Server“ genutzt.
- Flexibilität: MapReduce kann verschiedenste Aufgaben übernehmen – von Log-Analysen bis zu maschinellem Lernen.
5. Grenzen und Herausforderungen
So revolutionär MapReduce war – es hat auch klare Grenzen:
- Batch-orientiert: MapReduce ist für Batch-Jobs gedacht. Echtzeit-Analysen (z. B. Streaming) sind kaum möglich.
- Komplexität: Die Programmierung in MapReduce (Java, teilweise Python) ist vergleichsweise aufwendig. Entwickler müssen ihre Logik strikt in Map- und Reduce-Funktionen denken.
- Performance: Jeder Schritt schreibt Zwischenergebnisse auf die Festplatte → im Vergleich zu modernen In-Memory-Systemen wie Spark langsamer.
- Eingeschränkte Interaktivität: Ad-hoc-Analysen oder iterative Machine-Learning-Algorithmen sind umständlich.
Kurz gesagt: MapReduce hat Big Data möglich gemacht – aber moderne Technologien haben viele seiner Schwächen inzwischen überwunden.
6. MapReduce im Kontext moderner Big-Data-Architekturen
🔹 Hadoop-Ökosystem
MapReduce war das Herzstück von Apache Hadoop – zusammen mit HDFS (Hadoop Distributed File System). HDFS speichert riesige Datenmengen verteilt, MapReduce verarbeitet sie.
🔹 Spark als Nachfolger
Apache Spark hat MapReduce in vielen Bereichen abgelöst:
- In-Memory-Verarbeitung → schneller.
- Unterstützung von Streaming & Machine Learning.
- Einfache APIs in Python, R, Scala.
🔹 Heutige Rolle
MapReduce ist noch in vielen Legacy-Systemen im Einsatz. Auch wenn Spark und Co. dominieren, gilt: Wer Big Data verstehen will, muss MapReduce kennen. Es ist das Fundament, auf dem moderne Big-Data-Architekturen stehen.
7. Praxisbezug: Kundendaten & Adressdaten
MapReduce eignet sich hervorragend für große, wiederkehrende Datenaufgaben – auch im Bereich Kundendaten und Adressmanagement. Beispiele:
- Adressbereinigung in Massenbeständen
- Millionen Adressdatensätze werden parallel überprüft.
- Dubletten werden erkannt und konsolidiert.
- Datenvalidierung
- Postleitzahlen, Telefonnummern oder E-Mail-Formate werden überprüft.
- Fehlerhafte Einträge werden automatisch markiert.
- Kundensegmentierung
- MapReduce kann große Mengen an Transaktionsdaten aggregieren.
- Ergebnisse helfen, Zielgruppen für Marketingaktionen zu definieren.
Hier zeigt sich: MapReduce ist ein Bindeglied zwischen Data Governance (Regeln, Qualität) und Data Management (operative Umsetzung).
8. Fazit: Warum MapReduce verstehen wichtig bleibt
MapReduce war die Initialzündung für Big-Data-Technologien. Es hat gezeigt, wie man Daten in gigantischem Umfang parallel, skalierbar und fehlertolerant verarbeiten kann.
Auch wenn Spark und andere Frameworks heute leistungsfähiger sind, ist MapReduce nach wie vor relevant:
- als Bestandteil vieler bestehender Hadoop-Systeme,
- als Lernmodell, um die Prinzipien verteilter Datenverarbeitung zu verstehen,
- als Technologie, die den Weg für die heutige Big-Data-Landschaft geebnet hat.
👉 Wer Big Data verstehen will, sollte mit MapReduce beginnen – und danach den Blick auf Spark, Kafka und weitere moderne Frameworks richten.
9. Ausblick
Im einem späteren Blog schauen wir uns an, wie Apache Spark die Grenzen von MapReduce überwunden hat und heute eine Schlüsselrolle in modernen Datenplattformen spielt – von Echtzeit-Analysen bis hin zu KI-gestützten Prozessen.
Neugierig geworden?
Wir bei Address Consulting zeigen Ihnen, wie Sie mit moderner Big-Data-Technologie – von MapReduce bis Spark – Ihre Datenpotenziale voll ausschöpfen können.
